Capitulo 8 - Principios Básicos de Sincronização
8.3.2.1 Implemento de semáforos
8.3.2.2 Implementação de semaforos activos e passivos
8.4
Multiprocessadores com memória partilhada
A multiprogramação, partilha de tarefas e processamento paralelo tem
feito a cooperação de grupos sequênciais
de processos possivel. Operações
concorrentes tal como um grupo de processos relacionados permite uma aplicação
simples para aproveitar as
vantagens de paralelismo entre o cpu e dispositivos
I/O num uniprocessador mas também em cpu´s multiprocessador. Contudo,
a cooperação entre multiplos processos introduz potênciais novos problemas na
implementação de software, incluindo congelamento, a existência de secções
criticas e a possibilidade de indeterminação na computação.
Estes
problemas aumentam quando dois ou mais processos pretendem competir ou partilhar
recursos (incluindo informação).
É
importante compreender o súbito
potêncial da interação entre processos antes de tentar desenhar mecanismos
para suportar essas interações.
Por
isso a primeira parte deste capitulo discute a natureza geral dessas interacções.
O
resto foca as ferramentas classicas de sincronização, o semáforo, incluindo técnicas
de implementação.
A
sincronização é necessária em uniprocessadores , multiprocessadores e redes.
Contudo o problema é suficientemente mais complexo do que é primeiramente
estudado para o ambiente uniprocessador. Nesta discusão os resultados são
generalizados para multiprocessadores
(no
final do capitulo) e para redes (no capitulo 17).
As
edições de sincronização são dirigidas na ordem em que foram derivadas.
Fazendo
isto ajuda a explicar porque existe uma certa esquisitice em alguns aspectos das
soluções.
Numa exposição clássica, às vezes uma solução errada
é explicada antes de uma solução correcta ser dada para que possamos perceber
porque técnicas obvias provam ser inadequadas.
No capitulo 9, a discussão da sincronização é
estendida a um elevado nivel de
mecanismos.
Os
programas de computador são o conjunto de uma série de algoritmos –
procedimentos passo a passo para alcançar algumas tarefas de processamento de
informação.
O
uso de vários algoritmos para várias computações especificas é denominado
de programação, já desde os ultimos 500 anos.
Enquanto linguagens de programação populares tais como o
C e C++ tendem geralmente a desprezar a cooperação, a tecnologia do hardware básico
foi sistemáticamente em frente no uso de máquinas de computação distribuidas
e paralelas.
A
pressão económica e os requerimentos das aplicações forçou o uso de
hardware paralelo e distribuido.
Isto torna-se visivel em, por exemplo, sistemas contemporânios
de administração de informação, ambientes de computação de escritorios e
aplicações numéricas. Para ver esta aproximação no trabalho, veja “
In The Cockpit ” : resolvendo um sistema de equações lineares.
As
principais barreiras para o uso da cooperação para aplicações deriva do
software, como se mostra á frente:
Ø
Não existem linguagens de programação, usadas por
programadores de aplicações, que concordem amplamente. Enquanto a ADA (
Linguagem de programação usada pelo Ministério da Defesa dos EUA ) suporta
cooperação, o C e o C++ não.
Ø
A
tecnologia dos sistemas de software
não convergiram para uma programação padrão para programas cooperantes. A
aproximação usada no exemplo em “ In the Cockpit “ é único para este
exemplo.
Ø
Os sistemas operativos, normalmente, apenas fornecem os
mecanismos minimos para a cooperação, visto que há tantas maneiras de
implementá -la e nenhuma delas domina a área.
As técnicas aceitáveis para caracterizar
algoritmos cooperantes tem provado ser um sério impedimento para a
tecnologia de programação cooperante. O que torna
isto tão dificil para que não possamos formar um modelo de aplicação
para uma cooperação simples e proveitosa?
Os
sistemas de equações lineares são muito usados para servir de modelo a
problemas desde negócios, economia , investigação de operações, fisica,
engenharias entre outras disciplinas.Se nós representarmos um problema com três
incognitas, X1 X2 e
X3 , conseguimos determinar
valores para X1 X2 e X3 derivando três equações
lineares que expliquem relacionamentos entre as três variáveis como mostramos
a seguir:
a11x1+a12x2+a13x3=b1
a21x1+a22x2+a23x3=b2
a31x1+a32x2+a33x3=b3
Dadas
as três equações, podemos usar vários métodos numéricos para encontrar as
raizes de x1, x2 e x3. Visto que o nosso objectivo é ilustrar
como a cooperação pode ser aplicada a estes problemas, podemos
reescrever as equações da seguinte maneira:
x1=(b1-a12x2-a13x3)/a11
x2=(b2-a21x1-a23x3)/a21
x3=(b3-a31x1-a32x2)/a31
De
seguida, usamos uma estimativa inicial de x1(1),x2(1)
e x3(1) para computar uma segunda estimativa dos três
valores x1(2),x2(2) e x3(2).
Nós fazemos isto resolvendo as três equações ao mesmo tempo usando a
estimativa inicial de x1, x2 e x3. Isto pode
ser conseguido criando três processos para resolver equações e começando os
três processos ao mesmo tempo. Depois de terminarem os três processos, usando
x1(i-1), x2(i-2) e x3(i-3)
para produzir novos valores x1i, x2i
e x3i, eles tem que sincronizar-se ums com os outros para
ver se a computação convergiu para uma estimativa aceitavel. Depois da
sincronização, um processo vai substituir os valores nas equações para
confirmar o resultado. Se os valores corresponderem a computação está
terminada .
________________________________________________________________________________________________________________
Ø
Desenvolver
um conjunto de processos para que possam implementar cooperativamente uma aplicação
é surpreendentemente complexo. Uma reação é a variedade de paradigmas para
implementar a cooperação. Outro é a
dificuldade de lidar com as interacções e dependências.
Ø
É
especialmente dificil desenvolver software para manejar eficientemente com a
confusão dessas interacções na
rede de workstations e paralelo de processadores.
Ø
Mesmo com os mecanismos de alto nivel disponiveis é
dificil criar novos programas sem criar também novos problemas de sincronização.
Uma
computação paralela é feita de multiplas partes independentes que conseguem
ser executadas simultâniamente usando uma parte por processo. Em
algums casos as diferentes partes são definidas por um programa, mas em maior
parte dos casos são definidos por multiplos programas.A cooperação é
conseguida através de logica de partilha de memória que é usada
para partilhar informação e para sincronizar os processos que a
partilham. O
sistema operativo deve fornecer pelo menos a nivel base de mecanismos para
suportar a partilha e a sincronização
entre um grupo de processos.
Em
systemas de multiprogramação batch, ficheiros dentro do sistema de ficheiros são
partilhados. Um processo pode partilhar informação com outro, escrevendo a
informação num ficheiro que o outro pode abrir e ler. Muitos estilos de operações
simultâneas dos dois processos são quase impossiveis de atingir com este “granulado“
de informação partilhada. O processo tem que conseguir sincronizar usando um
mecanismo mais simples que o de partilha de ficheiros.
Os sistemas de partilha de tempo estimulam a necessidade
de uma partilha menos “granulada”, visto que um simples utilizador
pode ser capaz de criar dois processos e redireccionar a saida do primeiro para
a entrada do segundo. Os
pipes do Unix implementam este tipo de partilha. Esta capacidade de partilha
menos “granulada” assume
a existência simultânea de dois processos em comunicação.
Programas
cooperativos tem que ser construidos de forma a que os processos possam
partilhar informação, no entanto não interferirem um com o outro enquanto estão
na parte critica das suas respectivas execuções. Este requesito introduz um
problema de sincronização chamada de problema da secção critica.
Um
segundo problema é a ocorrência de deadlock´s durante a cooperação de
processos. Isto é, dois ou mais processos podem meter-se em situações
em que esperam por um recurso que outro processo necessita e que nenhum deles
pode prosseguir sem que um deles desista do recurso. Os
problemas da secção critica e dos
deadlock´s são discutidos seguidamente.
Suponha uma aplicação que é escrita de forma a que dois
processos, p1 e p2, cooperam para aceder a uma variavel interira comum, x. Por
exemplo, o processo p1, pode trabalhar com créditos para uma conta, enquanto p2
trabalha com débitos. O
proximo esquema de codigo mostra como os processos colocam a variavel balance
partilhada:
Shared
float balance; /*
variavel partilhada */
Esquema de
código para p1 Esquema
de codigo para p2
...
...
balance =
balance + amount; balance
= balance – amount;
...
...
Estas
instruções de linguagem de alto nivel vão ser compiladas em poucas instruções
de máquina, como as que vemos a seguir:
load
R1,balance
load
R1,balance
load
R2,amount
load
R2,amount
add R1,R2
sub R1,R2
store
R1,balance
store
R1,balance
O
problema da secção critica pode ocorrer quando os segmentos de código são
executados. Suponha que p1 está a correr num uniprocessador quando o intervalo
do timer acaba. Em particular, supondo que o processo p1 está a executar a
instrução
load
R2,amount .
Se
o escalonador (scheduler) selecionar em seguida o processo p2 para correr e este
executar o segmento de instrucção “balance = balance – amount; “ antes de p1 voltar a correr, então
vai existir “ condição de corrida “ entre p1 e p2. Se p1 ganhar a
corrida, os valores de R1 e R2 serão somados e a variavel balance não sobre
qualquer erro. Se p2 ganhara corrida, vai ler o resultado original de balance,
efectuar a subtracção ( balance – amount ) e guardar o valor em balance. Por
sua vez p1 que ainda tem o valor antigo de balance vai executar a soma e sobrepôr
o resultado ao anterior ficando a operação de subtracção perdida.
O programa que contêm p1 e p2 tem uma secção critica
quando há necessidade de partilhar a variável balance. Para
p1 a secção critica é quando soma amount a balance. Para p2 é quando subtrai
amount a balance. A execução cooperetiva de dois processos não é
garantidamente determinada, visto que duas execuções diferentes do mesmo
programa pode produzir valores diferentes. Na primeira execução p1 pode ganhar
a corrida e na próxima execução pode ser p2 a ganhar, resultando valores
diferentes nas variaveis partilhadas. Não é possivel detectar problemas apenas
considerando o processo ( ou programa ) p1 ou p2. Os problemas ocorrem devido á
partilha, não devido a um erro no código do programa. O problema da secção
critica pode ser evitado fazendo com que ambos os processos possam entrar na secção
critica desde que o outro não se encontre tambem na sua secção critica.
Como
é que dois processos podem cooperar para entrar na secção critica? Num
sistema multiprogramado, as interupções causam os problemas, visto que pode
fazer com que o escalonador funcione. Por causa das operações gravadas nos estados dos
registos implícito com troca de contexto, um processo pode resumir a execução
carregando informação inconsistente nos registos. Se o programador se
aperceber que a ocorrência de uma interrupção pode levar a resultados
errados, ele ou ela, podem fazer com que o programa desligue as interrupções,
enquanto se está a processar a secção critica do processo.
A
figura 8.1 mostra como, por exemplo, a secção critica pode ser programada
Figura
8.1
Desligar
as interrupções para implementar a secção critica.
Share double balance;
/* variáveis partilhadas */
Programa
p1
Programa p2
disableinterrupts();
disableinterrupts();
balance=balance+amount;
balance=balance-amount;
enableinterrupts();
enableimterrups();
usando
as instruções enableinterrupt e o disableinterrupt para evitar que ambos os
processos sejam iniciados ao mesmo tempo nas secções criticas. As interrupções
são desligadas quando os processos entram na secção critica
de forma a não serem interrompidos e voltam a ser ligados depois de esta
ser executada. Claro que, esta técnica pode provocar erros nos dispositivos de
entrada/saida (i/o) visto que podem vir a ser desligados durante muito tempo,
consoante os programas. Em particular, imagine que o programa entra num ciclo
infinito na sua secção critica. As interrupções iam ficar desligadas
permanentemente.
Uma alternativa para a solução da figura 8.1 não necessita que as
interrupções sejam desactivadas, dessa forma o problema de grande/infinitos
intervalos de computação é evitado. A ideia é fazer com que os dois
processos coordenem as suas acções sobre as variaveis partilhadas para
sincronizar os seus progressos. A figura 8.2 usa uma flag (bandeira) partilhada,
lock, de forma a que p1 e p2 possam coordenar aos seus acessos a balance. Quando
p1 entra na secção critica altera a variavel partilhada lock de forma a
prevenir que p2 entre tambem na sua secção critica. O mesmo acontece quando p2
entra na secção critica.
Figura
8.2
Secção
critica usando lock
Shared
boolean lock=FALSE;
/* variáveis partilhadas */
Shares
float balance;
Programa
para p1
Programa para p2
...
...
/*
adquirir o cadeado (lock ) */
/* adquirir o cadeado (lock ) */
while
(lock) (NULL;);
while (lock) (NULL;);
lock=TRUE;
lock=TRUE;
/*
executar a secção critica */
/* executar a secção critica */
balance=balance+amount;
balance=balance-amount;
/*
abrir o cadeado (lock) */
/* abrir o cadeado (lock) */
lock=FALSE;
lock=FALSE;
…
…
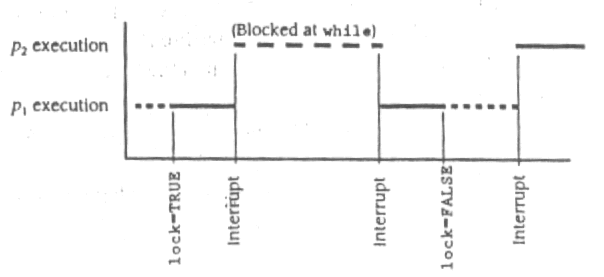
A figura 8.3 ilustra um modelo de execução para dois processos. Suponha
que p1 é interrompido durante a execução da frase
balance
= balance + amount;
depois
de ter alterado lock para TRUE e p2 começar a ser executado. Então p2 vai
esperar num ciclo while enquanto p1 termina e muda lock para FALSE.
Figura
8.3
O modelo de execução
Quando p1 mudar lock para FALSE indicou que p2 já pode
continuar, quando chegar a interrupção do relógio e ser a sua vez de executar.
Embora
o uso de lock para entrar na secção critica, estamos a acrecentar uma nova secção
critica relacionada com o teste da variavel lock. O
problema pode ocorrer quando acabamos de testar a variavel lock e nos preparamos
para alterá-la. Imaginemos que eramos interrompidos depois de testarmos a variável
lock. O
outo processo ainda ia ver lock=FALSE e entrava na seção critica. Quado fosse
a vez do primeiro voltar a correr iria mudar lock=TRUE mas o outro já lá
estava dentro. Para evitar isso podemos usar as interrupções mas desta vez por
pouco tempo, apenas para correr uma instrução como é mostrado na figura 8.4.
Figura
8.4
Manipulação de lock como secção critica
enter(lock){
exit(lock){
disableinterrupts(); disableinterrupts();
/*
loop enquanto lock=TRUE */
lock=FALSE;
while(lock){
enableinterrupts();
/*
deixa ocorrerem interrupcções */
}
enableinterrupts();
disableinterrupts();
}
lock=TRUE;
enableinterrupts();
}
As interrupções são desligadas por pouco tempo.
Numa situação de deadlock, dois ou mais processos entrão
num estado em que ambos seguram um recurso que o outro está a requisitar. Visto
que uma operação de requisição bloqueia a ligação até o recurso estar
disponivel, nenhum dos processos vai ter o recurso disponivel e vão ficar
bloqueados infinitamente.Na sincronização de processos, nós focamos os casos
em que o recurso é secção critica ou lock. O
capitulo 10 considera o problema geral em que o recurso pode ser qualquer
recurso no sistema.
Considere um caso em que dois processos p1 e p2 manipulam uma lista
comum. Uma
tarefa na manipulação da lista é o processo acrescentar ou apagar entradas,
outra é actualizar uma discrição do programa com o comprimento da lista. Quando
uma operação de apagar ou acrescentar ocorre, o comprimento tem que ser
actualizado. Podemos tentar a aproximação na figura 8.5 mas vamos ver mais
tarde que não chega para garantir o bom funcionamento do programa.
Figura 8.5
Multiplas variaveis partilhadas com sa interrupções desligadas
boolean lock1=FALSE
/* variaveis partilhadas */
boolean lock2=FALSE
shared list L;
Programa para p1
Programa para
p2
...
...
/*
Entrar na secção critica para
/* Entrar na secção critica para
apagar
um elemento da lista */
actualizar
o comprimento */
enter(lock1);
enter(lock2);
<Apagar
elemento>;
<Actualizar comprimento>;
/*
Sair da secção critica */
/* Sair da secção critica */
exit(lock1);
exit(lock2);
<Computação
intermédia>;
<Computação intermédia>;
/* Entrar na secção critica para
/*Entrar na secção critica para
actualizar
o comprimento */
acrescentrar
um elemento à lista*/
enter(lock2);
enter(lock1);
<Actualizar
comprimento>;
<Adicionar
elemento>;
/*
Sair da secção critica */
/* Sair da secção critica */
exit(lock2);
exit(lock1);
…
…
Se os processos p1 e p2 são executados ao mesmo tempo num systema
multiprogramado, uma interrupção do relógio pode ocorrer depois de p1 apagar
um elemento mas antes de ter actualizado o comprimento, então os dados na
descrição não são iguais aos dados reais. O processo deve executar as duas
operações ou então nenhuma. Para
não ocorrerem estes erros vamos modificar o nosso programa, como mostra a
figura 8.6.
Quando p1 entra na secção critica para
manipular a lista muda lock1 o que
previne p2 de entrar na sua secção critica. Depois de executada a secção
critica volta a mudar lock1 para o seu valor inicial. O mesmo acontece se for p2 a
entrar primeiro na secção critica.
Figura 8.6
Garantindo
que os valores relatados são correctos
boolean
lock1=FALSE
/* variaveis partilhadas */
boolean
lock2=FALSE
shared
list i,j;
...
...
/*
Entrar na secção critica
/* Entrar na secção critica
da
lista */
da descrição */
enter(lock1);
enter(lock2);
<Apagar
elemento>;
<Actualizar comprimento>;
<Computação
intermédia>;
<Computação intermédia>;
/*
Entrar na secçãp critica
/*Entrar na secção critica
da
descrição */
para i */
enter(lock2);
enter(lock1);
<Actualizar
comprimento>;
<Adicionar
elemento>;
/*
Sair das secções criticas */
/* Sair das secções criticas */
exit(lock1);
exit(lock2);
exit(lock2);
exit(lock1);
…
…
A
necessidade de interacções entre processos leva à necessidade de sincronização,
e a sincronização leva a problemas com secções criticas e deadlocks. FORK,
JOIN e QUIT são introduzidos no capitulo 6, como mecanismos para criar e
eliminar processos. Também são usados para sincronizar partes de uma computação
cooperativa.
shared
double x,y;
/*
variaveis partilhadas */
proc_A
{
proc_B{
while(TRUE){
while(TRUE){
<computa
A1>;
read(x); /*
consome x */
write(x);
/* produz x */
<computa B1>;
<computa
A2>;
write(y);
/* produz y */
read(y);
/* consome y */
<compute B2>;
}
}
}
}
Um semaforo é um tipo de sistema operativo de informação
abstrata que executa operações similares ás funções enter e exit descritas
na figura 8.4 . Antes de discutir os principios de funcionamento dos
semaforos,esta secção descreve as pretensões dos obstáculos do comportamento
do semaforo .
Como já foi discutido, um processo não pode entrar numa secção
critica se outro já se encontra na sua secção critica. Quando um processo está
prestes a entrar na sua secção critica, primeiro vai determinar se outro
processo já se encontra na sua secção critica. Se já se encontrar algum na
secção critica, o segundo processo sincroniza a sua operação
bloqueando-se até que o primeiro processo saia da sua secção critica.
Uma solução aceitavel para o problema da secção critica é requerida para
encontrar os seguintes obstáculos:
Ø
Apenas um processo pode entrar na sua secção critica de
cada vez (exclusão mútua).
Ø
Supondo que a secção critica está livre. Se um grupo de
processos indica que quer entrar, apenas esse grupo de processos vai entrar na
zona de seleção.
Ø
Quando um processo tenta entrar na sua secção critica, não
pode ser adiado indefenidamente mesmo que não exista outro processo na secção
critica.
Ø
Depois de um processo requerer entrar na secção critica,
apenas um número limitado de processos é permitido entrar na suas secções
criticas antes do processo original
entrar na sua secção critica.
O problema da secção
critica é um problema de software na sua formulação tradicional. Para propósito
de discussão, esta secção assume tambem como pontos altos outros aspectos
importantes do problema considerando o esqueleto de dois processos mostrados
abaixo na figira 8.9.
Figura
8.9
Cooperação
de processos
proc_0(){
proc_1(){
while(TRUE)
{
while(TRUE) {
<secção
de computação>;
<secção de computação>;
<secção
critica>;
<secção
critica>;
}
}
}
}
<declarações
globais partilhadas>
<processamento
inicial>
fork(proc_0,
0);
fork(proc_1,
0);
As seguintes pretensões são
feitas sobre o esquema do software na figura:
1-
Escrever e ler uma celula de memória comum a dois processos é uma operação
indivisivel. Qualquer tentativa de dois processos executarem simultâneamente
operações de escrita ou leitura resulta em vários ordenamentos desconhecidos,
mas as operações não vão ocurrer ao mesmo tempo.
2-
Não é suposto haver prioridades entre os processos no caso de dois ou
mais processos quererem entrar na secçáo critica.
3-
As velocidades relativas dos processos são desconhecidas, por isso o
mesmo programa pode demorar intervalos de tempo a executar .
4-
Como é indicado na figura 8.9, os processos são supostos serem
sequenciais e ciclicos.
Um semaforo, s, é uma variavel inteira não negada que só
é alterada ou testada por uma de duas rotinas de acesso:
V(s) : [s=s+1]
P(s)
: [while (s=0) (wait) ; s=s+1]
Os parêntises rectos que
cercam as expressões nas rotinas de acesso indicam que as operações são
indivisiveis ou atómicas. Na operação V, o processo que executa a rotina não
pode ser interrompido até completar a rotina. A operação P é mais complexa.
Se s é maior que 0, é testado e decrementado como uma operação indivisivel.
Por outro lado se s é igual a 0, o processo que executa a operação P pode ser
interrompido
Figura
8.10
Uso de semáforos nas secções criticas
proc_0()
{
proc_1() {
while(TRUE){
while(TRUE){
<secção
de computação>;
<secção de computação>;
P(mutex);
P(mutex);
<secção
critica>;
<secção critica>;
V(mutex);
V(mutex);
}
}
}
}
semaphore
mutex = 1;
fork(proc_0,
0);
fork(proc_1,
0);
Existem algumas considerações
práticas relacionadas com a implementação do semáforo. O resto desta secção
lida com como implementar semáforos e como ver os semaforos como recursos.
8.3.2.1
Implemento de semáforos
A figura 8.4 mostra como as interrupções podem ser
desligadas para manipular a variavel lock. A mesma técnica pode ser usada para
implemtar operações V e P. Visto que P e V são implementados como funções
do sistema operativo, o modelo de uma solução assume que os processos do
utilizador podem ter um ponteiro para o semáforo, mas o ponteiro é para um
objecto no sistema operativo.
Uma implementação que siga este modelo desliga as interrupções, mas
apenas por pequenos periodos de tempo (ver Figura 8.17). Quando um processo
bloqueia num semaforo, as interrupções estão ligadas; As interrupções estão
desligadas apenas quando é manipulado o valor do semaforo. Isto tem dois
efeitos importantes:
Ø
Há efeitos minimos no sistema I/O.
Ø
Enquanto um processo segura um semáforo, previne apenas a
entrada de outros processos na secção crítica. Todos os outros processos não
são afectados pelo facto do processo estar na secção crítica.
Os semáforos podem ser implementados sem desligar as
interrupções se o hardware fornecer algumas condições especiais. Uma
implementação directa das instrucções
P e V é razoavelmente dificil devido á necessidade de acomodar o ciclo wait na
operação P. Em vez disso, uma implementação uniprocessador geralmente quer
interagir com o escalonador para a implementação de P, logo uma parte da
instrucção vai ser implementada em hardware e outra em software. O sistema
operativo pode criar recursos abstratos para cada semáforo. Depois usa um
recurso de gestão bloqueia processos que executam operações P como se
tivessem executado uma operação de requerimento num recurso convencional. A
garantia vem como o recurso de gestão do semaforo consegue implementar
simultameamente e correctamente os acessos ao semáforo sem usar as interupções.
As instrucções TS (test and set) são o caminho dominante para
conseguir os efeitos P e V. TS é uma instrução simples que pode de incluido
no repertório da máquina sem muito esforço. Mas isto pode fazer a implementação
de semaforos muito simples. A local de memória TS, m, ou TS(m), é carregado
para um registo do CPU, e na memória é escrito o valor TRUE.
Para um processo entrar na secção crítica vai ler a memória. Ao
comparar o valor de m o processo para ou
segue.
8.3.2.2
Implementação de semaforos activos e passivos
Um semaforo pode ser visto como um recurso de consumo. Um
processo bloqueia se o valor requisitado a um semaforo não está disponivel. Um
processo move-se de um estado de execução para um estado bloqueado executando
uma operação P num semaforo de valor zero. O processo passa do estado
bloqueado para executavel quando é lido um valor positivo no semaforo; ele
decrementa o semaforo enquanto muda de estado. Quando um processo larga um
recurso, neste caso executa uma operação V, o alocador de recursos move o
primeiro processo de bloqueado para pronto.
8.4
Multiprocessadores com memória partilhada
As secções 8.1 e 8.3 descrevam uma técnica para
implementação de semaforos desligando interrupções. Num multiprocessador com
memória partilhada, isto é insuficiente, visto que desligando as interrupções
num CPU não afecta o comportamento dos outros processadores. Por isso
multiprocessadores com memória partilhada comercializados usam instrucções
especificas como TS para
implementar semaforos. Em multiprocessadores com partilha de memória, a memória
pode ser projectada para suportar TS.