DEADLOCKInstituto Politecnico de Tomar
Departamento de Engª Electrotécnica
SISTEMAS OPERATIVOS 2000/2001
Trabalho nº 1: Tradução e resumo do capitulo 10 do livro:
"OPERATING SYSTEMS: A modern prespective"
Gary J. Nutt
Realizado por: Nelson Valador nº3201
(Paralização Completa)
«Deadlock é um problema significativo que pode surgir numa comunidade que coopera ou compete por processos. Deadlock foi introduzido no Capítulo 7 no contexto de sincronização onde muitos exemplos diferentes de Deadlock foram considerados nas várias discussões de sincronização. Este capítulo generaliza a discussão para aplicar a recursos administrados pelo gerente de recurso. O problema é especialmente interessante porque, em geral, sua ocorrência depende das características de dois ou mais programas diferentes e de processos que executam esses diferentes programas ao mesmo tempo. Os programas poderiam ser executados repetidamente por vários processos diferentes sem encontrar Deadlock e então ficarem em deadlock por causa de algum padrão de uso de recurso complicado. Há três estratégias gerais para pensarmos em Deadlock: prevenção, avoidance(formas de evitar), e, detecção e recuperação. Este capítulo dá-nos bases para estudar o problema usando modelos de processos simples e recursos, de forma simples.Depois considera a aproximação usada em cada destas estratégias. »
Dijkstra descreve um abraço mortal que pode acontecer entre um grupo de dois ou mais processos devido ao facto de cada processo segurar pelo menos um recurso enquanto faz um pedido de outro. O pedido nunca pode ser satisfeito porque o recurso pedido está a ser segurado por outro processo que é bloqueado á espera do recurso que o primeiro processo está a segurar. Figure 10.1 ilustra um abraço mortal, ou deadlock , entre três processos sobre três recursos. Os três processos poderiam ter posto o sistema no estado mostrado na figura executando como segue:
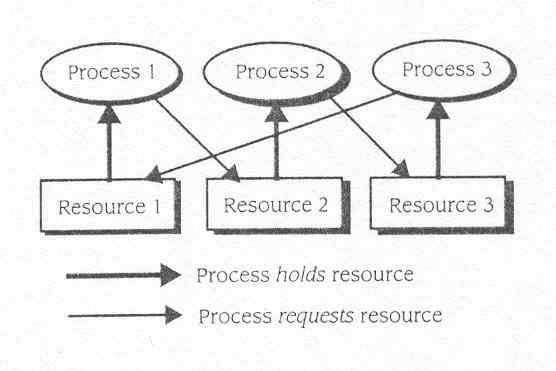
Fig10.1 Três processos em deadlock
Processo 1 está segurando Recurso
1 e está pedindo Recurso 2; Processo 2 está segurando Recurso
2 e pedindo Recurso 3; Processo 3 está segurando Recurso 3 e está
pedindo Recurso 1. Nenhum dos processos pode proceder porque tudo estão
esperando por um recurso segurado por outro processo bloqueado. A menos
que um dos processos descubra a situação e pode retirar seu
pedido para um recurso e disponibilizar esse recurso , nenhum dos processos
poderá correr. Podem ser envolvidos os gerentes de recurso e outros
processos de sistema operacional em uma situação de deadlock
. Suponha um processo de aplicação muito grande deseja adquirir
um bloco de disco por um pedido para um alocador de recurso de disco. Quando
o processo de aplicação foi activado, foi alocado quase toda
a memória primária pelo gerenciador de memória. Agora
suponha o gerenciador de alocação de disco é um processo
trocado fora da memória primária .Ele requer para memória
de forma a que possa ser carregado para satisfazer o pedido de bloco de
disco, mas o processo de aplicação não disponibilizou
memória livre suficiente para o alocador de bloco de disco ser carregado!
Como é mostrado em Figura 10.2, o processo de aplicação
e o processo de distribuição de disco está em deadlock.
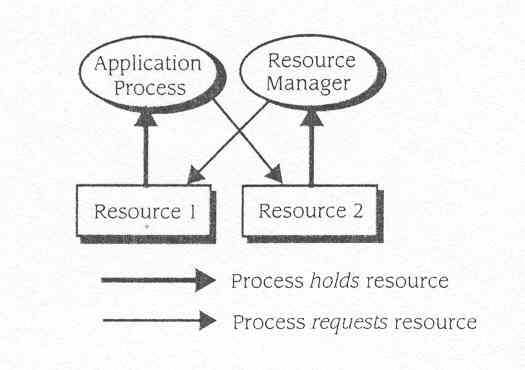
Fig10.2 Deadlock entre uma aplicação e o sistema operativo
Deadlock também acontece no
mundo real. Provavelmente o exemplo mais famoso é gridlock(paralisação
em grelha) entre automóveis em tráfico condicionado. Gridlock
acontece quando as quatro ruas de uma só mão ao redor de
um quarteirão têm tráfico condicionado neles e automóveis
entram nas intersecções em uma tentativa para progredir (veja
Figura 10.3) .No exemplo, um fluxo de automóveis que viajam ao longo
de uma rua de uma só mão corresponde a um processo e cada
intersecção é um recurso compartilhado. Os automóveis
de cada direcção seguram o recurso de intersecção
de outra direcção o que provoca um engarrafamento e consequente
paralisação do transito.
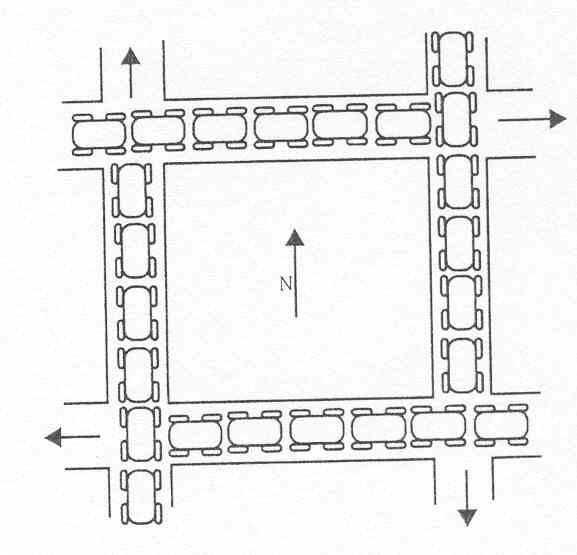
Fig10.3 Gridlock entre automoveis
No Capítulo 7, Deadlock foi introduzido como um efeito colateral de estratégias de sincronização. Porque dois processos desejaram actualizar um par de variáveis compartilhadas de uma maneira consistente, eles usaram uma flag(bandeira) de lock(fechadura) para assegurar que quando o valor de uma variável for mudado, o valor da outra variável seria actualizado. Situações semelhantes frequentemente ocorrem periodicamente em comunidades de processos que estão compartilhando qualquer tipo de recursos. De facto, isso é por que um recurso é definido como sendo qualquer coisa do que um processo precisa de modo a prosseguir -de consumo ou reutilizável. Memória, uma mensagem, um valor de semáforo positivo - todos são recursos. Um processo pode bloquear quando pede quaisquer destas entidades; logo qualquer um pode contribuir para acontecer deadlock.
Deadlock é uma condição global . Se nós analisássemos um programa para qualquer processo envolvido em Deadlock , nós não acharíamos nenhum erro discernível. O problema não está num único processo, mas na acção colectiva do grupo de processos. Como, então, pode ser esperado que um programador lide com um Deadlock? Um programa individual geralmente não pode descobrir Deadlock , visto que está bloqueado e impossibilitado usar o processador para fazer qualquer trabalho. A detecção de Deadlock deve ser efectuada pelo sistema operativo. Como sistemas operativos podem ser construídos para assegurar que um Deadlock é dirigido correctamente? Há quatro aproximações básicas:
Suponha as condições seguintes se referem ao modo como um processo usa recursos:
Estratégias de evitar confiam
na habilidade de um gerente de recurso para predizer o efeito de satisfação
de pedidos de alocação individuais. Se um pedido pode conduzir
a uma situação de deadlock, estratégias de "avoidance"
recusarão o pedido. Considerando que "avoidance" é uma aproximação
de predictiva, confia em informação sobre a actividade do
recurso que estará a ocorrer para o processo. Por exemplo, se um
processo anuncia com antecedência o número de máximo
de recursos que pedirá, é possível evitar deadlock
quando são feitos pedidos de recurso específicos. Esta estratégia
é chamada reivindicação máxima e será
tratada na Seção 10.4. "Avoidance" é uma estratégia
conservadora. Tende a subtilizar recursos recusando alocá-los se
existir o potencial para deadlock. Por conseguinte, é raramente
usado em sistemas operacionais modernos.
Alguns sistemas são projectados
para permitir distribuição de recursos para proceder sem
intervenção particular. Ao invés, o sistema vê
se existe deadlock, periodicamente ou sempre que certos eventos ocorram.
Um aspecto difícil desta aproximação é determinar
quando o algoritmo de descoberta deve ser executado. Se for executado muito
frequentemente, isto desperdiçará recursos de sistemas. Mas
se não for frequentemente corrido, processos bloqueados e recursos
de sistemas serão utilizados de uma forma não produtiva até
o sistema ser recuperado. Este problema acontece porque a presença
deadlock na não ocorrência de eventos em vez da ocorrência
de algum evento excepcional que poderia activar a execução
do algoritmo de descoberta.
Quando um algoritmo de descoberta
é accionado, há duas fases para a estratégia. Primeiro
é a fase de detecção durante a qual onde se vê
de existe deadlock. Se deadlock for descoberto, o sistema passa para a
segunda fase, a recuperação, através de recursos preemptivos
de processos. Esta recuperação significa que a condição
de não preempção foi violada e serão seleccionados
e destruídos os processos.
Qualquer trabalho que eles podem ter
realizado antes do deadlock serão perdidos. A estratégia
de detecção e recuperação é a estratégia
de deadlock mais usada em sistemas comerciais. As condições
debaixo das quais é invocado são frequentemente determinadas
manualmente quer dizer, o operador do computador invoca o algoritmo de
descoberta manualmente quando o sistema parece ser inactivo.
Muitos sistemas comerciais não levam em conta a
possibilidade de deadlock. Os fabricante só consideraram maior importância
comercial ás estratégias de deadlock quando este se torna
suficientemente dispendioso para o fabricante.
Deadlock de um sistema pode ser estudado usando um modelo para representar o estado de distribuição de recursos dos componentes do sistema. Isto pode ser feito modelando todo o estado do sistema em qualquer momento e identificando então quais os estados de deadlock. Dado a existência de tal um modelo conceptual, a pessoa pode definir as características que causam deadlock e então usar o modelo para determinar políticas para implementar "avoidance", prevenção, e estratégias de detecção.
Esta secção descreve um modelo de processos e recursos que podem ser formalizados num modelo matemático preciso. P será um conjunto de n processos diferentes e R um conjunto de m recursos diferentes onde cj é o número de unidades de tipo de recurso Rj no sistema. Logo, como os recursos podem ser alocados aos vários processos devem ser definidos. Como a distribuição de recursos para mudanças de processos muda ao longo da execução do processo , o modelo tem que refletir cada uma destas mudanças. Um modo útil para mostrar este tipo de comportamento é usar um diagrama de transição de estado. Assim o estado no modelo representa o padrão de pedidos de recurso e distribuições que existem no sistema em qualquer momento particular -o estado do modelo representa o estado do sistema. No sistema, as mudanças de estado quando são pedidos recursos, alocados, ou desalocados, e neste modelo, transições de estado acontecem para representar um pedido, distribuição. e operações de desalocação. S será um conjunto de estados no modelo que representa estados correspondentes no sistema. O estado inicial é s0; isto representa a situação na qual todos recursos não estão alocados. Todos os outros estados, sj, representam possíveis estados de sistema, assim cada estado modelo representa quais unidades de todo recurso estão sendo pedidas ou seguradas por cada processo. Os detalhes de como um estado especifico pode ser representado são considerados quando nós examinamos estratégias de deadlock individuais nas Secções 10.4 e 10.5 (estratégias de prevenção não usam definições de estado para lidar com um deadlock).
Para agora, vamos focar as transições de estado. O padrão no qual recursos são pedido, adquirido, e não alocados determina se o sistema está deadlocked. Este padrão corresponde à lista de transições que acontecem na transição modelo de estado. Todas as outras actividades do processo não são pertinentes ao estudo de deadlock, assim eles são ignorados neste modelo. Num conjunto de processos, P,. qualquer processo. Pi Î P, poderia causar uma transição de estado dependendo se qualquer pi
Até mesmo se pi é bloqueado em sj, algum processo diferente de pi poderia mudar o estado do sistema de sj para um novo estado sk onde pi poderá proceder. Se nós podemos determinar que não há nenhuma série de transições de estado que conduzem o estado actual para outro onde o processo pi está desbloqueado, então o processo nunca poderá ser executado novamente -pi está deadlocked em sj.Por outras palavras, o processo pi está deadlocked em sj se para todo sk que pode ser alcançado por alguma série de transições de sj, pi está ainda bloqueado em sk. Se há qualquer processo deadlocked num estado sk , então sk é chamado um estado de deadlock.
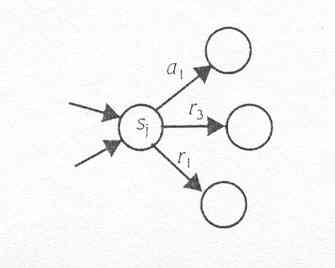
Fig10.4 Estado onde p2 está bloqueado
Para acontecer deadlock num sistema, todas as quatro das
condições listadas na Secção 1 0. 1. 1--exclusão
mútua, segura e espera, espera circular(continua), e não
preempção -deve segurar recursos ao mesmo tempo. Estratégias
de prevenção asseguram que pelo menos uma das condições
sempre é falsa. A condição de exclusão mútua
não pode ser invalidada, considerando que assegura que um recurso
só pode ser usado por um processo de cada vez. Por exemplo, se um
programa de aplicação está sendo executado por um
único processo e este pediu que uma "tape" particular fosse montada
numa "tape drive" e permite outro processo para ter acesso ao "tape drive"
não faria sentido. Enquanto pode ser possível violar a condição
de exclusão mútua para alguns recursos, como UNIX faz
para uma exibição de terminal, não
é possível fazer assim para todo tipo de recurso num sistema
convencional. Estratégias de prevenção têm que
focar nas outras três condições.
A condição de segura-e-espera
impede um processo de segurar alguns recursos enquanto pedindo outros.
Há dois modos em que esta condição pode ser violada.
Ou pode ser exigido a um processo pedir todos os seus recursos quando é
criado. Ou, a condição de segura-e-espera pode ser violada
exigindo para o processo largue todos recursos actualmente segurados antes
de pedir qualquer outro. Esta aproximação posterior é
extrema, visto que requer que um processo compita para todos os recursos
que quer cada vez que pede qualquer recurso incremental.
Sistemas de grupo(batch) operam em
trabalhos, cada um dos quais são implementados um único processo
(veja Capítulo 1) .Visto que um trabalho de grupo é definido
por um " arquivo " de trabalho que contém todos os comandos aplicados
ao trabalho, é possível simplesmente requerer as declarações
de controle de trabalho para identificar todos os recursos necessários
para executar o trabalho do início. Quando todos os recursos estão
disponíveis, o trabalho/processo podem ser colocados na lista pronta
a executar e executou na suposição que nunca pedirá
mais recursos durante sua execução. Esta estratégia
faz com que um trabalho adquira recursos que só possa usar para
uma fase pequena num trabalho e segurá-los durante a duração
do trabalho, tornando-os assim indisponíveis para outros trabalhos.
Trabalhos de grupo são frequentemente executados durante horas.
Consequentemente, esta técnica resulta em utilização
pobre de recursos. Um efeito directo é que os recursos ficam mais
difíceis de obter, assim o processamento no sistema pode ser reduzido
comparado a um sistema semelhante sem política de prevenção.No
caso extremo, um trabalho pode sofrer "fome" simplesmente devido a recurso
não disponível. Num modelo de transição estado
para esta estratégia, está a natureza das transições
é ter todos os pedidos antes de qualquer aquisição
ou desalocação de eventos , (veja Figure 10.7) .Se o sistema
está no estado sj e pi faz pede qualquer recurso , então
pi tem que pedir todos os recursos de que precisa. Assim há uma
única transição devido ao pedido de pi para algum
estado novo,sk. Do estado sk, o sistema pode alocar os recursos pedidos
por pi. Ou alguns outros processos podem causar uma transição
para um estado novo antes que aconteça a alocação.
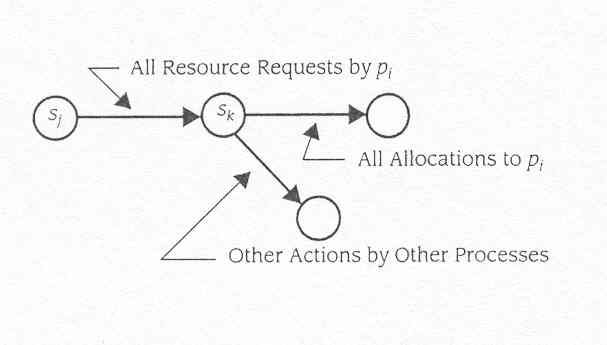
Fig10.7 Requerer todos os recursos antes de inciar
Sistemas interativos não requerem
que todos os comandos, nem até mesmo todos os processos, sejam conhecido
na ocasião a interação começa. Ao invés,
o usuário pode criar processos novos, apagar existentes, executar
comandos que pedem processos novos,
e assim por diante a qualquer hora durante uma sessão.
A primeira estratégia de segura-e-espera não é plausível
neste tipo de ambiente. Ao invés, esta segunda estratégia
pode ser usada para evitar a condição de segura-e-espera:
Cada vez que é requerido um novo recurso
por um processo, tudo os seus recursos atualmente segurados
são postos num estado estável, persistente, e então
libertado. Por exemplo, arquivos abertos são fitas fechadas e montadas
são rebobinadas e descarregadas. A seguir , o processo tenta a readequirir
os recursos
juntamente com qualquer novo recurso que possa precisar
e evitando assim a condição de segura-e-espera de ser verdade.
Isto tende a subutilizar recursos e pode encorajar "fome".
Também no fragmento de modelo
de transição de estado genérico para a segunda estratégia
(Figura 10.8), transições de pedido têm que acontecer
antes de qualquer aquisição ou desalocação
de transições. Porém, estes diagramas de estado são
mais complexos que estes para o estado de grupo, desde que eles têm
que recuperar transições de desalocação para
o estado inactivo de processo. Isto é feito para capturar os cenários
no qual um processo determina dinamicamente se precisa mais recursos.
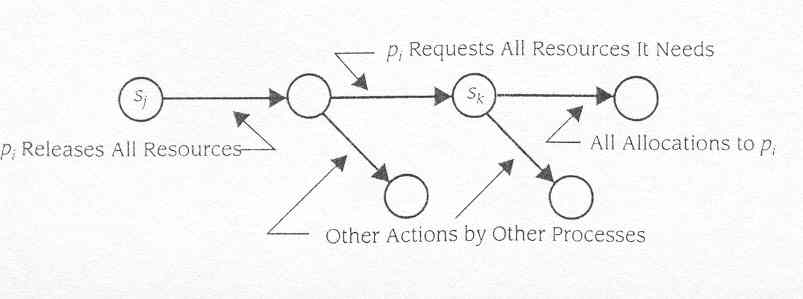
Fig10.8 Disponibilizar todos os recursos antes de pedir mais
Esperas circulares acontecem quando
há um conjunto de n processos, {pi}, que contem unidades de um conjunto
de n recursos diferentes, {Rj}, tal como pi segura Rj enquanto pede unidades
de um recurso diferente no conjunto. Por outras palavras, cada dos n recursos
é segurado por n processos, mas cada processo então requer
unidades indisponíveis de um dos tipos de recurso segurado por outro
processo. Uma espera circular é refletida pela relação
de recurso-processo, assim o modelo de transição de estado
não ajuda no estudo deste problema.
Suponha que nós usamos uma representação
gráfica que produz uma descrição mais detalhada de
cada estado e então usa este " micro modelo " de cada estado para
descobrir uma condição de espera circular. Sendo que um quadrado
representa um tipo de recurso, um círculo representa um processo,
uma extremidade (pi, Rj) denota que pi tem um pedido pendente para unidades
de Rj, e uma extremidade (Rj, pi) significa que pi segura unidades de Rj.
Usando este modelo, a Figure 10.9
descreve os detalhes de um estado no qual a condição de espera
circular é verdade. O condição é evidente pelo
ciclo no gráfico composto do nós representando recursos e
processos. A representação gráfica dá-nos a
perspicácia para como prevenir esperas circulares. O alocador de
recursos têm que assegurar que o sistema nunca alcança um
estado no qual o gráfico interno contém um ciclo. (As condições
são realmente mais complexo que a descoberta de um ciclo simples
porque cada recurso pode ter unidades múltiplas de um recurso. Isto
ficará evidente quando nós consideramos algoritmos de descoberta.
A condição de ciclo é suficiente para representar
uma espera circular só se cada tipo de recurso tem só uma
unidade do recurso.)
Uma técnica para prevenir a ocorrência de
uma condição de espera circular é estabelecer uma
ordem total em todos os recursos num sistema, por exemplo usando um índice
numérico para cada deles. Os recursos são então R1,
R2, ...Rm, onde Ri <Rj se i <j.
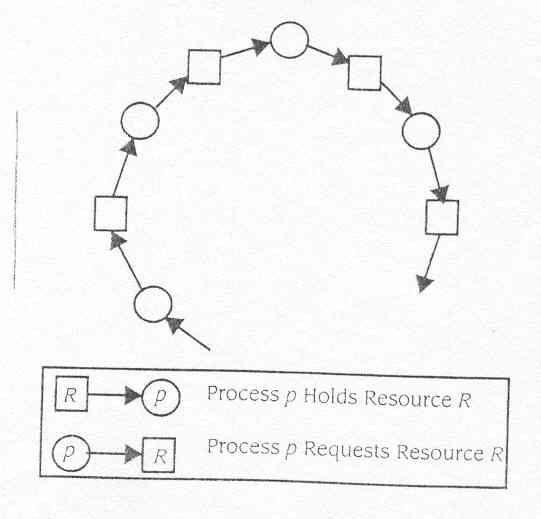
Fig10.9 Um modele de um estado com espera circular
Suponha que nós só permitimos
a um processo adquirir um recurso, Rj, se Ri <Rj para todos os outros
recursos, Ri, actualmente segurado pelo processo. Um processo só
pode pedir unidades de Rk se todos os indices de Rh forem menores que os
indices de todo Rk para o Rh que o segura.A ordem total tem que estabelecer
ordem em todas as unidades de recurso tal como também tipos de recurso
se as unidades forem distinguíveis. Também tem que incluir
recursos consumíveis como também reutilizáveis. Como
na situação de segura-e-espera, se um pi requer um recurso,
Rj, tal que Rj <Rk, por algum Rk atualmente, segura, então a
política vai
requerer que pi deixe todos os Rk, adquirir Rj, e então
readquirir Rk. O efeito no desempenho de processo será negativo.
visto que este método pode aumentar só o tempo que processos
têm que esperar por recursos para ficar disponível.
Suponha que o sistema operativo permitiu
processos para "voltar atrás de" um pedido para um recurso se o
recurso não estivesse disponível. Por exemplo, o de sistema
poderia ser implementado de forma que sempre que um processo pede um recurso,
o sistema,
imediatamente ou responde alocando o recurso ou
indicando que existem recursos insuficientes para satisfazer o pedido.
Em casos nos quais recursos são indisponível, o processo
pedido ou apura junto do gerente de recurso até que as unidades
desejadas ficam disponíveis ou faz outro trabalho. (Esta aproximação
implícita assume que o processo tem outro trabalho útil para
fazer isso não requer o recurso especificado. Uso da estratégia
requer a linguagem de programação e paradigma para apoiar
tal aproximação.) O diagrama de estado para um sistema que
permite um processo para preemptir o seu pedido diferirá de um não
permitindo isto.
A Figura 10.11 descreve informalmente
como o modelo de estados muda como resultado de um processo podendo fazer
isto. Se o sistema está num estado si e o processo pu faz um pedido
,ru, então as transições de sistema para um estado
novo, sj. Agora, desde que pu é informado que os recursos que pediu
não estão disponíveis, passa o sistema para o estado
si com uma nova transição, wu (w quer dizer o pedido está
retirado pelo processo isso está causando a transição).
Consequentemente, o sistema regressa agora no estado posterior ao pedido
de pu. Neste momento, qualquer pu pode pedir o recurso novamente (passar
o sistema novamente para sj )ou um processo diferente, pv, pode causar
uma mudança de estado de sistema fora de si para um novo processo
sk ,por exemplo desalocando recursos. O novo estado sk podem ser mais vantajosos
para pu porque permite a pu para obter os recursos pedidos que eram indisponíveis
em si. O modelo representa o caso no qual pu continua apurando votos junto
do gerente de recurso. Esta técnica não pode ser caracterizada
como " preempção total " cheio de recursos de processos (como
requeridos num procedimento de recuperação) contudo é
suficiente prevenir um deadlock. Infelizmente, não há nenhuma
garantia que esta técnica será efectiva, visto que o sistema
pode chegar a um conjunto de estados por meio de uma comunidade de processos
está apurando por recursos que são segurados através
de outros processos dentro do conjunto. Enquanto tecnicamente o sistema
não está em deadlock ,não funcionará corretamente
devido a um fenômeno chamado livelock ,que significa um conjunto
de transições causa transições no diagrama
de estados, mas nenhum das transições é eficaz a longo
prazo.
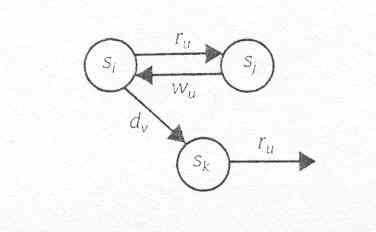
Fig10.11 Diagrama de estado com preepção
Como a estratégia de prevenção,
estratégias de "avoidance"são uma aproximação
conservadora para distribuição de recursos. Eles controlam
transições de estado permitindo o sistema para fazer uma
transição só como resultado de uma alocação
quando é certo que dedlock não pode acontecer devido a pedidos
subsequentes. A estratégia é analisar o estado de prespectiva
-antes de entrar nisto - determinar se lá existe qualquer sucessão
de transições fora do estado no qual todo processo ainda
se pode executar.
A estratégia de "avoidance"
depende de informação adicional acerca das necessidades a
longo prazo de cada processo. Em particular, quando um processo é
criado tem que declarar a sua reivindicação máxima
- o número de máximo de unidades que o processo vai pedir
-para todo tipo de recurso. O gerente de recursos pode honrar o pedido
se os recursos estiverem disponíveis. Pode determinar se há
sucessão de pedidos, alocações,e desalocações
que habilitam todos processos para eventualmente "correr" até á
sua conclusão se todos os processos usam o seu numero máximo
de recursos.
Com a aproximação de
"avoidance" o sistema é mantido sempre num estado seguro. A análise
é executada na altura de um pedido, então, tem que se considerar
o estado de alocação de todos os recursos e os recursos adicionais
pendentes que um processo pode requerer até sua reivindicação
máxima. É importante notar que a análise de estado
não prevê que todo processo na verdade pedirá sua reivindicação
máxima. Isto somente procede debaixo da suposição
que se todo processo fosse exercitar a sua reivindicação
de máximo, então ainda haveria alguma sucessão de
distribuições e desalocações que permitiria
o sistema a satisfazer os pedidos de todo processo.
Um estado de sistema no qual esta
garantia não pode ser feita é um estado inseguro.A Figure
10.12 é uma descrição intuitiva de como uma comunidade
de processos possa operar num estado seguro e como a comunidade faz com
que o sistema se aventura em estados inseguros. Como indicado pelo fluxograma
da figura, normalmente os programas são executados com menos que
a reivindicação máxima e só requer ocasionalmente
o máximo da quantia de um recurso para uma fase de computação.
Depois da fase intensiva do recurso ser completada, o processo reverte
para a operação com uma quantidade de recurso mais moderada
.
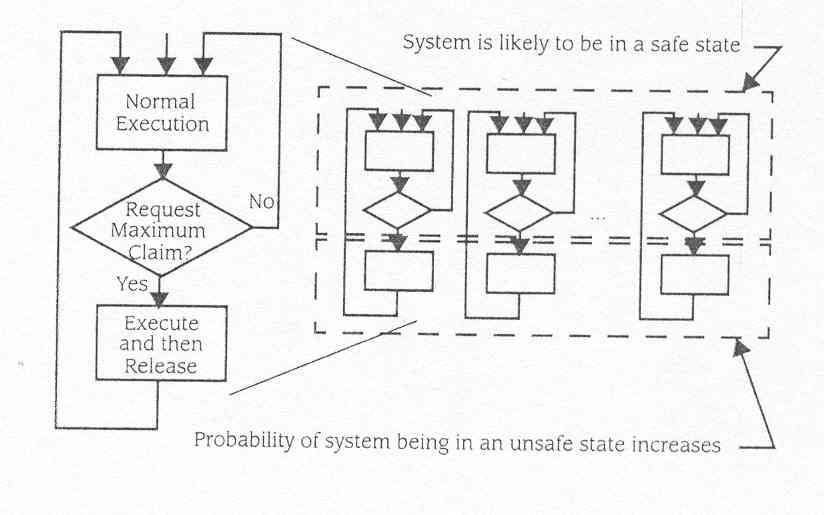
Fig10.12 Estratégia de estado seguro
Contanto que os processos tendam a
usar menos que a sua reivindicação máxima , é
provável (mas não garantido) que o sistema esteja num estado
seguro. Porém, se um número grande de processos tiverem necessidade
de um grande numero de recursos , ao mesmo tempo, os recursos de sistemas
tenderão a ser fortemente usados e a probabilidade do sistema ser
inseguro é maior. A estratégia é então determinar
se qualquer pedido pendente está satisfeito, e todos os programas
requerem a sua reivindicação máxima. Esta exigência
significa o alocador de recursos bloqueará alguns processos enquanto
outros usam a sua reivindicação máxima e então
permitirão os processos que estão á espera ,proceder.
O sistema pode não ser capaz garantir todas as reivindicações
máximas podem ser encontradas -o estado é inseguro- mas alguns
processos podem não executar a sua reivindicação máxima
até sistemas voltar um estado seguro.
Recorde que se um estado é
inseguro, não significa o sistema está em deadlock ou até
mesmo que um deadlock é iminente (veja Figura 10.13). Isto quer
dizer que o assunto está fora " das mãos " do alocador de
recurso e será determinado somente por acções futuras
dos processos. O diagrama de estado ilustra que o sistema pode ir para
estados inseguros mas entretanto voltar para estados seguros, dependendo
das acções levado pela comunidade de processos. Contando
que o estado esteja seguro, o alocador de recursos, podem ser garantidos
de modo a evitar deadlock.
A estratégia de avoidance depende
da análise de um estado de sistema particular e determinar se está
seguro. Isto significa nós precisamos de um modelo mais detalhado
de cada estado no modelo de transição estado de forma que
nós pode fazer juízos aproximadamente segurança. O
modelo clássico de um estado usado na estratégia de avoidance
vem da analogia de Dijkstra de alocador de recurso e de como bancos funcionam(o
algoritmo do banqueiro) .
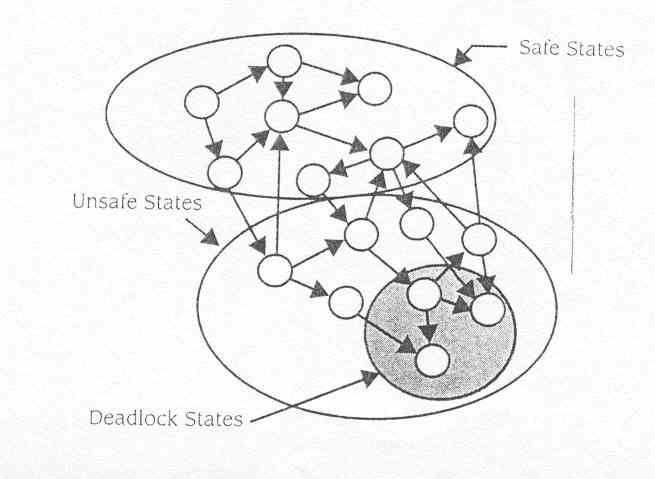
Fig10.13 Estado de deadlock ,seguro e inseguro
A descoberta e estratégia de
recuperação permite ao gerente de recurso ser muito mais
agressivo sobre distribuição que faz a estratégia
de avoidance. Considerando que algoritmos de avoidance evitam estados inseguros
até mesmo se o de sistema podesse recuperar deles, algoritmos de
detecção e recuperação ignoram a distinção
entre estados seguros e inseguros -são permitidos os gerentes de
recurso alocar unidades sempre que eles estão disponíveis.
Se processos parecem estar bloqueados em recursos por desordenadamente
longo tempo, o algoritmo de descoberta é executado para determinar
se o estado atual é deadlock. Algoritmos de descoberta não
fazem nenhuma predição sobre estados que puderam sido alcançado
do estado actual, embora eles determinarão se existe qualquer sucessão
de transições nas quais todo processo pode ser desbloqueado.
Foram definidos recursos como " qualquer
coisa que um processo precisa para proceder ". Como apontado anteriormente,
esta necessidade poderia ser um bloco de memória primário,
um arquivo, ou um acesso exclusivo a um dispositivo. São chamados
tais recursos seriamente reutilizáveis porque um processo pede o
sistema operativo para alocar o recurso exclusivamente para o processo
e o processo vai depois largar o recurso para outro processo usar de novo.
Unidades individuais de recursos seriamente reutilizáveis empregam
uma rígida aproximação tempo compartilhando multiplexado
.
Processos também usam recursos
consumiveis. Por exemplo, quando um processo bloqueia numa operação
de leitura que está a tentar para ler o próximo caracter
de um teclado, então o caráter é necessitado pelo
processo para proceder. Porém, quando processo adquire o caracter,
nunca o largará. Instantes das duas classes de recurso é
tratado diferentemente pelo gerente de recurso e processa tem propriedades
teóricas diferentes com respeito a análise de deadlock.
As próximas vários subsecções
consideram recursos seriamente reutilizáveis e recursos consumiveis
e então explica como os sistemas que contêm ambas as classes
de podem ser analisados recursos para detectar deadlock.
Recursos seriamente reutilizáveis representam recursos
de hardware tradicionais e suas abstracções. Para nossa análise
de deadlock , recurso seriamente reutilizável, Rj, tem um finito
número de unidades idênticas tal que o seguinte tem:
Recursos consumíveis diferem
dos recursos seriamente reutilizáveis em que um processo possa pedir
recursos consumíveis mas nunca os largará. Um recurso de
consumivel típico é um sinal, mensagem, ou introdução
de dados. Porque tais recursos possa ter um número ilimitado de
unidades e porque alocou unidades não são disponibilizadas,
o modelo para analisar recursos seriamente reutilizáveis não
se aplica recursos consumíveis. Porém. ao redefinir o modelo
para consumo consumivel, podem ser achadas condições para
testar um estado de sistema para deadlock.
Um recurso consumível, Rj,
tem um número ilimitado de unidades idênticas tal que os seguintes
têm:
. O número de unidades do recurso, wj,varia.
(wj é usado em vez de cj para enfatizar que o número de unidades
disponíveis
para um recurso consumível difere do número fixo de unidades
para um recurso seriamente reutilizável.)
. Há um ou mais processos produtores,pp,que podem aumentar wj
. Processes de consumidor,pc , diminuição de wj para Rj.
Da mesma maneira que nós usamos um gráfico de recurso reutilizável como um micro modelo para considerar as propriedades de um recurso seriamente reutilizável , usam-se um gráfico de recursos consumíveis para definir um micro modelo para analisar as propriedades de recursos consumíveis:
Sistemas reais incorporam uma combinação
de recursos reutilizáveis e consumíveis.
Estratégias de detecção
de deadlock precisam combinar as técnicas de análises de
recursos de consumo e reutilizável.
Enquanto a definição formal de gráficos de recurso
geral e as análises para detectar deadlock não estão
incluídas aqui, tal sistema, tem um conjunto de recursos determinado
pela união de recursos de consumo e reutilizável. As condições
necessárias e suficientes para um deadlock num gráfico de
recurso geral é uma combinação das condições
para gráficos de recurso de consumo reutilizável onde são
se aplicadas as regras que aplicam a cada classe correspondendo a subconjuntos
de recursos num gráfico de recursos geral. A análise de detecção
é administrado usando reduções de gráfico de
recurso reutilizáveis em todos recursos reutilizáveis e reduções
de recursos de consumo recurso gráfico em recursos consumíveis.
Para um estado para estar livre de deadlock, os recursos
reutilizáveis devem ser isolados completamente através de
reduções. Porém, o gráfico de recursos consumíveis
tem que ter uma sucessão na qual cada processo pode ser demonstrado
para não ser bloqueado.
Uma vez detectado o deadlock num sistema,
o sistema terá que ser recuperado mudando-o para um estado no qual
não há nenhum processo em deadlock. Claro, isto significa
um ou mais processos terão que ser preemptivos, disponibilizando
então os seus recursos de forma a que os outros processos em deadlocked
possam desbloquear. Em alguns casos, o mecanismo de recuperação
pode usar o gráfico geral de recursos para seleccionar processos
para destruir. Mais tipicamente, o operador simplesmente começa
destruindo processos até o sistema pareça estar novamente
operacional. A aproximação de força é reiniciar
a máquina e destruir assim todos os processos .
Como já foi dito, quando recursos
são preemptidos de um processo, o processo,normalmente é
simplesmente destruído.
Porém, às vezes o processo pode ser removido sem destruir
todo do trabalho já realizado. Isto é realizado incorporando
um mecanismo de checkpoint/rollback no sistema por qual um processo periodicamente
tira uma "fotografia" do seu corrente. O sistema operativo grava o checkpoint
para o processo, e o processo continua então a sua actividade. Se
o sistema operativo determina que um processo é envolvido em deadlock,
destrói o processo e disponibliza assim os seus recursos para outros
processos usarem. Logo, restabelece o estado do processo da vítima
(incluindo relocando recursos e rescrevendo arquivos para o estado anterior)
baseado na informação do checkpoint e então reinicia
o processo do último checkpoint .
Depois que um processo seja destruído,
o algoritmo de detecção de deadlock é invocado novamente
ver se a recuperação teve êxito. Se foi, o sistema
continua normalmente a operação. Se não for, então
outro processo é preemptado. O algoritmo de recuperação
remove eventualmente processos em deadlock, potencialmente reiniciando
todos menos um dos processos envolvidos no deadlock. Então o sistema
continua operação normal.
Deadlock cria uma situação
na qual um ou mais processos nunca correrão para conclusão
sem recuperação. Pode ser prevenido projectando os gerenciadores
de recurso de forma que eles violem pelo menos um das quatro condições
necessárias para deadlock: exclusão mútua, segura
e espera, espera circular, e não preempção. Prevenção
pode ter efeito em sistemas de grupo mas normalmente não é
prático em timesharing ou outros sistemas interactivos.
O estado do processo-recurso modelo
prevê uma armação para definir deadlock independente
da estratégia escolhida para tratar de deadlock. O modelo permite
a definição precisa de deadlock em termos de diagrama de
estado. É muito usado nas discussões subsequentes de avoidance
e detecção e recuperação. Deadlock pode ser
evitado usando informação adicional, como reivindicação
máxima em cada tipo de recurso para cada processo, , para não
pôr o sistema num estado inseguro. O algoritmo do banqueiro é
o algoritmo de avoidance clássico. É intuitivamente semelhante
à operação de um banco que está oferecendo
linhas de crédito a seus clientes, até mesmo quando a soma
das linhas de crédito excede os recursos totais do banco. Semelhantemente,
o algoritmo do banqueiro usa a reivindicação máxima
para determinar se uma operação de alocação
conduzirá a um estado no qual o gerenciador de recurso não
pode garantir que deadlock não acontecerá. O algoritmo do
banqueiro executa efectivamente as mesmas operações usadas
no algoritmo de detecção do algoritmo de redução
de gráfico .
Avoidance é demasiado conservadora e não
é frequentemente usado em sistemas operativos contemporâneos.Detecção
e estratégias de recuperação diferenciam entre recursos
reutilizáveis e consumíveis num sistema. Algoritmos de detecção
usam reduções de gráfico para explore transições
de estado que poderiam ocorrer do estado que está sendo analisado.
Os detalhes de um passo na redução de gráfico dependem
se a redução é aplicado a um recurso consumível
ou reutilizável. Uma vez determinado um estado em deadlock , o sistema
operativo invocará um algoritmo de recuperação para
remover processos já envolvidos no deadlock até que a condição
não exista. Este capítulo completa a discussão de
administração de processos..