Processos e sincronização
Introdução
A sincronização de processos apareceu devido a necessidade de partilhar recursos num computador, esta partilha necessitava de coordenação para assegurar um correcto funcionamento.
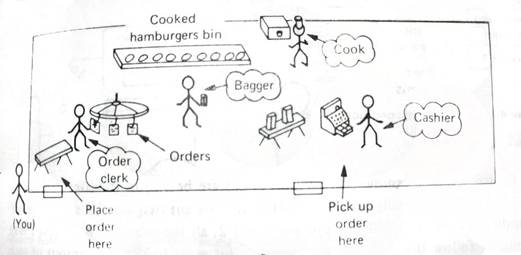
EXEMPLO: HAMBÚRGUER
Começamos por fazer o nosso pedido ao empregado de balcão ele por sua vez coloca o pedido numa mesa, em que outro empregado trata do pedido (um de cada vez), na cozinha existe sempre um empregado a fazer hambúrgueres mantendo assim o stock. Neste exemplo cada pessoa (processo) opera em grande parte individualmente sendo as divisões partilhadas o único método de comunicação entre eles.
Este exemplo tal como outros, permite-nos encontrar diversas formas de comunicação e cooperação (exemplo: o que faz o emprego que trata dos pedidos quando não os há? Vai dormir...
Situações similares acontecem no mundo dos computadores com o tratamento de processos. Em alguns casos a coordenação é imposta pelo sistema operativo. Associado com a alocação e comunicação entre processos estão relacionados 2 problemas de sincronização: o “race condition” e o “deadly embrace”.
1 – Race condition
“Race
condition” resulta da partilha de dados e recursos entre dois ou mais
processos, a figura 1
ilustra um exemplo de partilha de recursos por parte de dois processos. Neste 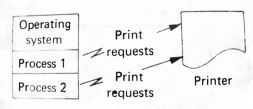 exemplo
assumimos que os dois processos estão a correr, cada processo ocasionalmente
pede para que uma linha seja impressa na impressora. Dependendo da prioridade
de cada um dos processos pode ser impresso primeiro o processo 1 e só depois o
processo 2 ou vice-versa.
exemplo
assumimos que os dois processos estão a correr, cada processo ocasionalmente
pede para que uma linha seja impressa na impressora. Dependendo da prioridade
de cada um dos processos pode ser impresso primeiro o processo 1 e só depois o
processo 2 ou vice-versa.
Uma das soluções para o uso de recursos consiste em que o processo explicite que recursos quer usar, antes de usar e só depois do processo deixar de precisar deste recurso é que ele é libertado, para ser usado por outros processos, caso um processo requisite um recurso que esteja em uso, fica automaticamente bloqueado e assim que o recurso esteja disponível o processo é desbloqueado e começa a usar esse recurso.
Para além da partilha de recursos físicos existe também a partilha de outros recursos tais como as tabelas, que necessitam do mesmo tipo de sincronização.
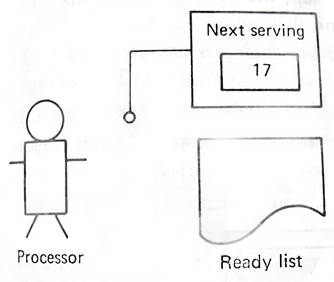
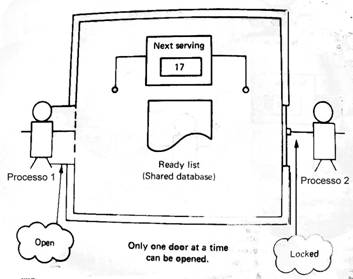
Temos como exemplo a figura 2, que consiste num método para seleccionar um processo de uma lista e coloca-lo a “correr”, este método funciona bem só com um processo, mas se tivermos mais que um processo o método não funciona, tal como indica a figura 3.
|
Figura 2 Quando
o processo que está a correr termina: 1
– Procura o processo na lista de pronto. 2
– Marca o processo que está completo. 3
– Toma nota do número do próximo serviço (número 17). 4
– Procura o processo 17 na lista de pronto. 5
– Marca o processo para ser acabado. 6
– Ajusta a lista de pronto para o próximo serviço. |
|
|
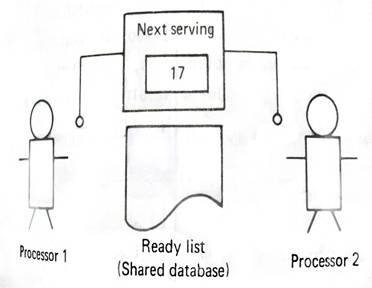
Figura 3 Assumindo
que ambos os processos terminam ao mesmo tempo: 1
– Processador 1 encontra o processo 1 na lista de pronto. 2
– Processador 2 encontra o processo 2 na lista de pronto. 3
– Processador 1 marca o processo 1. 4
– Processador 2 marca o processo 2. 5
– Processador 1 toma nota do próximo serviço (17). 6
– Processador 2 toma nota do próximo serviço (17). 7
– Processador 1 procura o processo 17 na lista de pronto e toma nota. 8
– Processador 2 procura o processo 17 na lista de pronto e toma nota. 9
– Processador 1 ajusta a lista de pronto para o próximo serviço (18). 10
– Processo 2 ajusta a lista de pronto para o próximo serviço (18). Ambos
os processadores estão a trabalhar num dos métodos 18 e o outro foi ignorado. |
|
 Assumindo
agora que dois processos, cada um num processador, ficam bloqueados
aproximadamente ao mesmo tempo. Depois de se salvar o estado em que se encontra
cada processo, cada um dos processadores ira determinar qual o próximo processo a ser servido. Como ambos os processadores usam
independentemente o mesmo algoritmo, eles iram escolher o mesmo processo.
Assumindo
agora que dois processos, cada um num processador, ficam bloqueados
aproximadamente ao mesmo tempo. Depois de se salvar o estado em que se encontra
cada processo, cada um dos processadores ira determinar qual o próximo processo a ser servido. Como ambos os processadores usam
independentemente o mesmo algoritmo, eles iram escolher o mesmo processo.
Este problema é o resultado directo de múltiplos processadores a processarem bases de dados comuns sem qualquer tipo de sincronização.
Para resolver este problema, os processadores que operarem independentemente tem de ser sincronizados tendo em conta o acesso a bases de dados comuns, a figura 4 ilustra este mecanismo.
Antes de aceder a lista de uma base de dados, o processador tem de verificar um específico bit “lock bit” caso este não esteja activo, a base de dados não está a ser usada, então o processador activa o bit e pode começar a operar na base de dados. Quando acabar o processador desactiva o bit, caso haja outro processador que necessite da base de dados e esta não estiver disponível terá de esperar até que o bit esteja desactivado.
2 - Mecanismos de sincronização
Vários mecanismos de sincronização estão disponíveis para providenciarem vários mecanismos de coordenação entre processos.
2.1– Instrução “TEST-AND-SET”
Em muitos esquemas de sincronização necessário uma entidade física para representar um determinado recurso. Esta entidade física é muitas vezes chamada de “lock bit”.
0 – significa
que o recurso está livre e 1 significa que o recurso está ocupado
1 – Examina o valor do “lock bit” (ou 0 ou 1).
2 – Coloca o valor a 1.
3 – Caso o valor original do “lock bit” seja 1 volta ao passo 1.
Depois do processador ter usado o recurso coloca o “lock bit” a zero.
2.2– Mecanismos de “WAIT AND SIGNAL”
O mecanismo de “WAIT AND SIGNAL” pudesse considerar razoável para sincronização mas desperdiça muitos recursos em termos de processamento. O processo que é bloqueado na realidade está continuamente em loop verificando o “lock byte” e esperando que ele mude para zero. Podemos definir os mecanismos de “lock” e “unlock” assim:
“LOCK (X)”:
1 – Examina o valor do “lock byte” ( pode ser 1 ou 0).
2 – Coloca o valor a 1.
3 – Caso o valor seja 1 chama o “WAIT(X)”.
“UNLOCK (X)”:
1 – Coloca o “lock byte” a 0.
2 – Chama o “SIGNAL (X)”.
O “WAIT AND SIGNAL” é um método primitivo de controlo de tráfego do gerenciador do processador.
2.3 – Operadores P e V em semáforos
É um mecanismo mais geral de “LOCK/UNLOCK”, em que assume valores para além do 0 e 1. O mecanismo pode ser definido como:
P (S):
1 – Decrementa valores de S (S = S – 1).
2 – Caso S seja inferior a 0 então entra em “WAIT”.
V (S):
1 – Incrementa valores de S (S = S + 1).
2 – Se S for inferior ou igual a 0 então entra no “SIGNAL (S)”.
Caso um dos semáforos tenha o valor 1 então o P(S) e o V(S) entram no estado de “WAIT(S)” e “SIGNAL(S)”.
2.4 – Comunicação de Mensagens
Este método permite com que haja comunicação directa entre processos através de métodos de ENVIO(Pr, M) e RECEPÇÃO(Ps, M), em que Pr e Ps são processos e M é a mensagem. O ENVIO(Pr, M) salva a mensagem M para o processo Pr, a RECEPÇÃO(Ps, M) devolve a mensagem M, caso ela exista, para o processo que “requisitou” a RECEPÇÃO.
3 – Deadly Embrace
 Uma
situação “deadly embrace” acontece quando dois processadores estão a espera de
um determinado recurso e esse recurso está retido num dos processadores, o que
faz com que os processadores estejam parados.
Uma
situação “deadly embrace” acontece quando dois processadores estão a espera de
um determinado recurso e esse recurso está retido num dos processadores, o que
faz com que os processadores estejam parados.
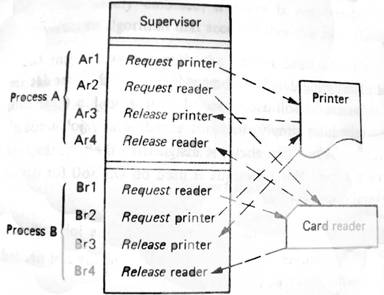
Figura 5, o processo A e B estão ambos a partilhar a impressora e um leitor de cartões e devido aos processadores não estarem a trabalhar em sintonia as operações de requisição e libertação podem ser interceptadas de diversas maneiras.
1 – Ar1, Ar2, Ar3, Ar4, Br1, Br2, Br3, Br4
2 – Br1, Br2, Br3, Br4, Ar1, Ar2, Ar3, Ar4
3 – Ar1, Ar2, Br1, Ar3, Ar4, Br2, Br3, Br4
O leitor deve assegurar-se que os dados que esta a receber são lógicos, no caso 3 o processo B fica bloqueado no Br1 até terminar o processo A em Ar4.
O problema do deadly embrace, é que pode acontecer de muitas maneiras e multi-programação, especificamente no uso de tabelas partilhadas, para lidar com este tipo de problema usa-se os seguintes métodos:
1 – Pré-localizar todos os recursos partilhados
2 – Limitar as Alocações
A – Alocação controlada
B – Alocação Standard
3 – Detectar e recuperar
3.1 – Pré-localizar todos os recursos partilhados
Uma maneira simples de evitar os deadly embraces consiste em o utilizador declarar todos os dispositivos e recursos que esteja a utilizar, fazendo com que não faça mais nenhum trabalho até que não estejam disponíveis todos os recursos para a execução do trabalho actual, ficando esses recursos bloqueados enquanto estiverem ser usados. Esta técnica é usada nos OS/360 para alocação de dispositivos, mas existe algumas desvantagens.
1 – Um utilizador pode não saber antes do tempo de execução quais são os dispositivos a ser usados.
2 – É necessário esperar até que todos os recursos estejam disponíveis, mesmo que alguns não sejam necessários até ao fim da execução.
3 – É um desperdício para o sistema ter de bloquear um determinado recurso a um processo podendo este nem vir a ser usado.
4 – Um determinado trabalho pode não precisar de usar todos os recursos durante todo o tempo de execução.
3.2.1 – Limitar as alocações para evitar o deadly embrace
 No
ponto 2.1 o utilizador tem de especificar todos os recursos de maneira a que um
trabalho pudesse ser executado. Este ponto consiste em evitar alocar recursos a
um trabalho caso haja alguma hipótese da existência de um deadly embrace. Por
exemplo se um sistema tiver 9 tapes e um trabalho necessitar de usar 6 tapes e
houver outro trabalho que necessita de 6 tapes, se seguir-mos o OS/360 o
primeiro trabalho irá requisitar as 6 tapes e só as irá libertar quando estiver
terminado seguindo o método de alocação controlada o sistema iria permitir com
que ambos os trabalhos corressem ao mesmo tempo até chegarem a uma situação de
possível deadly embrace, este método permite apenas com que 1 trabalho continue
a correr a partir desse momento ficando o outro parado até estejam disponíveis
mais tapes.
No
ponto 2.1 o utilizador tem de especificar todos os recursos de maneira a que um
trabalho pudesse ser executado. Este ponto consiste em evitar alocar recursos a
um trabalho caso haja alguma hipótese da existência de um deadly embrace. Por
exemplo se um sistema tiver 9 tapes e um trabalho necessitar de usar 6 tapes e
houver outro trabalho que necessita de 6 tapes, se seguir-mos o OS/360 o
primeiro trabalho irá requisitar as 6 tapes e só as irá libertar quando estiver
terminado seguindo o método de alocação controlada o sistema iria permitir com
que ambos os trabalhos corressem ao mesmo tempo até chegarem a uma situação de
possível deadly embrace, este método permite apenas com que 1 trabalho continue
a correr a partir desse momento ficando o outro parado até estejam disponíveis
mais tapes.
1 – Este método tem de declarar que recursos vão utilizar.
2 – Antes de requisitar um recurso o sistema vai verificar toda a sequência a procura de um possível deadly embrace, caso não o encontre requisita o recurso figura 6
O maior problema deste método é que continuamos a ter de indicar antecipadamente os recursos que vamos utilizar.
3.2.2 – Alocação standard
A alocação standard é outro método de limitar as alocações. Neste método todos os recursos têm um número único (exemplo: impressora = 1, tape = 2, disco =3, etc.) e todos os pedidos de alocação tem de ser em ordem decrescente, isto é, impressora(1), tape(2), disco(3) ou impressora(1), disco(3), o método estabelece que enquanto de se seguir este esquema um pedido de alocação é aceite e assim garantindo que não haja deadly embrace, mas mesmo assim este método tem vários problemas, isto é, a sequencia que nós somos obrigados a usar pode não corresponder a sequencia que nós precisamos (exemplo: podemos precisar primeiro de usar o disco e depois a impressora). Na generalidade dos casos, este método só é usado em casos muitos específicos, temos como exemplo o OS/MVT que usa este método para localizar as tabelas internas do sistema.
3.3 – Detectar e recuperar
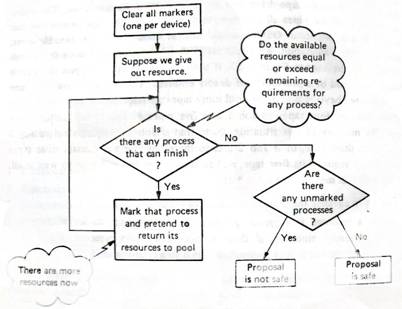
Os métodos anteriores não permitem que haja deadly embrace, este método ao contrário dos anteriores permite que haja deadly embrace deste que o possa detectar e depois recuperar, o método que se segue pode ser usado para detectar deadly embraces:
1 – Arbitrariamente assinala-se com um número para cada recurso e cada processo.
2 – Cria tabelas para não perder rasto dos recursos e processos tal como mostra na figura 7.
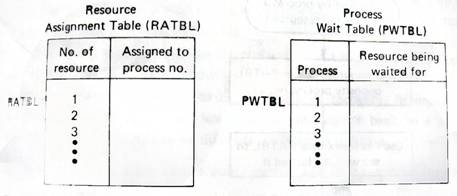
3 – Cria entradas RATBL e PWTBL à medida que os recursos são redimensionados e libertados.
1 – Quando um recurso bloqueado é requisitado, é usado um algoritmo para detectar deadly embraces tal como é ilustrado na figura 8.


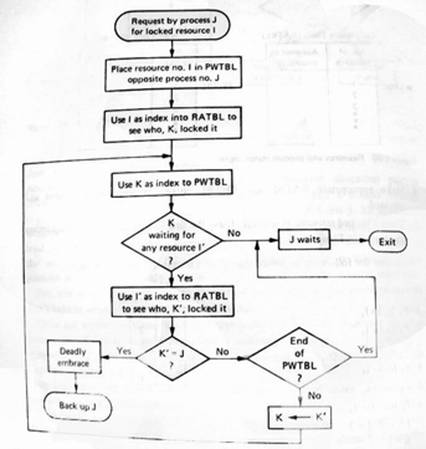
Com este método não é necessário ordenar recursos, a libertação de recursos pode ser monitorizada pelo controlo de tráfego e os recursos podem ser requisitados novamente, com algumas alterações no RATBL e no PWTBL.