Capítulo11
Gestão de Memória
Como enfrentar com ... espera ..está-me na ponta da língua.
-Dave Barry , Dave Barry Turns 40
Objectivos do capítulo
O sistema de memórias inclui todas as partes do computador utilizadas no armazenamento de informação. A memória secundária é uma memória muito mais persistente, isto é, sustenta no armazenamento dispositivos como as hard drives. A memória primária sustenta a informação enquanto está a ser executada e tem um acesso mais rápido do que a memória secundária, contudo é mais volátil do armazenamento. Um desafio na programação é manter o programa de informação na memória primária só enquanto estiverem a ser usadas pelo CPU e para escrever informação de volta na memória secundária e para escrever informação de volta na memória secundária rapidamente depois de ter sido usada ou actualizada. Se o desafio é encontrado, o processo usa uma menor quantidade de tempo de execução. Também, o perigo de perder informação processada por quebra ou inconsistência é também reduzida.
A gestão de memória è responsável pela atribuição á memória primária de processos e pela assistência do programador no carregamento e armazenamento de conteúdos da memória primária. Gestão de repartições de memória primária e minimizar o tempo de acesso á memória é o objectivo básico á atingir na gestão de memória.
Este primeiro capítulo considera as questões básicas no design da gestão de memória. Em seguida, irá focar-se nos gestores de memória de armazenamento de atribuições de tarefas. Gestores de memória contemporânea ajudam os programadores de aplicações a conhecerem a gestão de memória desafiada por ligações dinâmicas e carregando partes dos espaços de endereços na memória primária, e este capítulo discute aspecto chave de como fazem isto: ligando endereços atrasados. A ultima secção do capítulo descreve as estratégias básicas de emprego da gestão da memória moderna: permutar, memória virtual e caching.
11.1 – O Básico
O computador de Von Neuman incorpora uma unidade de memória primária para sustentar dados e programas quando estão preparados para ser usados por um processo que é executado no CPU. A unidade de memória primária é parte da memória executável ( e é às vezes chamada memória executável ), desde que a unidade de controlo CPU só consiga trazer instruções desta memória . Os dados podem ser carregados no registo ALU da memória primária ou armazenados nos registos da memória primária. O computador de Von Neuman também incorpora vários dispositivos, incluindo armazenamento de dispositivos. Quando dados e programas são para ser executados, são carregados na memória primária; por outro lado, são guardados na memória secundária ( no armazenamento de dispositivos.
O objectivo do gestor de memória é administrar o uso da memória primária , incluindo o automático movimento de programas e dados para traz e para diante entre as memórias primária e secundária. Esta secção discute várias questões básicas que dirigem e forçam o design de gestão de memória e o seu funcionamento. São considerados requisitos básicos, emergência de hierarquias de memória, e os procedimentos clássicos para a criação de espaços de endereçamento e localizá-los na atribuição da memória primária. Depois de estudar esta secção, os estudantes devem de estar preparados para olhar para o espaço de atribuição no gestor de memória, que é incluído na secção seguinte.
11.1.1 – Requisitos na memória primária
Memória primária e CPU são as fontes fundamentais usadas por todos os processos. Sem memória, o processo não tem lugar no intuito de executar programas e dados. Os capítulos 6-10 focam-se em como um sistema operativo implementa processos, com início da gestão do CPU no capítulo 7.Este e o próximo capítulo olham pelo design dos gestores de memória primária.
Há três requisitos básicos que guiam o design de memória:
Será sempre possível construir uma memória que pode ser acedida pela alta velocidade do CPU. Um registo é como uma memória. Contudo, estas memórias são muito caras de construir, desta forma CPU´ s modernos contêm tipicamente menos de 100 registos. Na tecnologia dos dias de hoje, o tempo de acesso à memória primária é de 1,5 a 4 vezes mais longo que o tempo de referencia de um registo de CPU. Contudo, a unidade de memória primária deve ter acima de 100 MB de memória, ora rudemente um milhão de vezes mais de memória executável que tem um registo de CPU. Mesmo embora estes números mudem rapidamente ( guiados por tecnologias de memória e factores comerciais ), a relação velocidade e tamanho tendem a estar relativamente constantes.
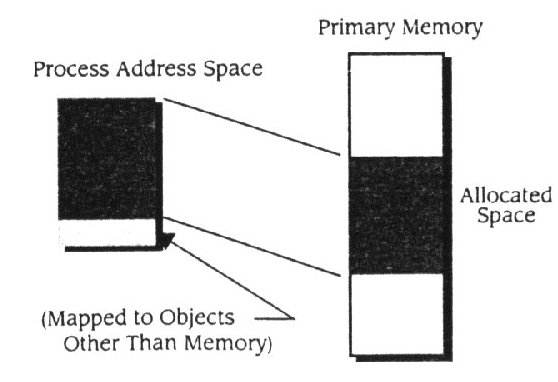
Gestores de memória desenvolveram-se com os sistemas operativos e as tecnologias de hardware. Contudo, hoje em dia os processos modelo usam essencialmente o mesmo interface de memória que era usado em 1960. Um processo é provido com um espaço de endereçamento que é parte na atribuição de memória primária do processo de mapeamento no espaço de endereçamento ( Fig. 11.1 ).
Figura 11.1
O relacionamento entre o espaço de endereçamento e a memória primária
A proposta do gestor de memória é :
O problema da implementação de uma maior e eficiente memória envolve as duas tecnologias hardware e software. O hardware desenvolveu-se de forma a aceder a grandes unidades no menor tempo, a estratégia de gestão de memória foi alterada para ter vantagem nestes melhoramentos. Reciprocamente, como a estratégia de gestão de memória foi desenvolvida, o hardware foi guiado a incorporar funções especializadas. O contínuo desenvolvimento nas estratégias de gestão de memória nos computadores contemporâneos requerem que os seus designers tenham um profundo conhecimento sobre software e hardware.
Desempenho de sintonização
Usando as hierarquias de memória para reduzir o tempo de acesso
Os sistemas de computadores de Von Neuman empregam três ou mais níveis de memória, dispostos em hierarquias. O mais alto é ocupado pelos registos de memória do CPU, o nível do meio é ocupado pela memória primária ( executável ) e o nível mais baixo pela memória secundária. Os níveis das memória primária e secundária podem ser redefinidos em níveis empregando tecnologias específicas de memória. Dentro das hierarquias, o nível mais alto de memória tende a ser muito rápida mas limitada em termos de tamanho. A memória do nível mais baixo é muito grande, enquanto que a velocidade de acesso é uma consideração secundária. Neste nível são armazenadas grandes quantidades de informação ( por exemplo : terabytes ) por grandes períodos de tempo (por exemplo : anos ). Neste baixo nível o custo do armazenamento ainda é uma preocupação, a fita magnética ainda é extremamente usada, mesmo sabendo que a sua velocidade de acesso é lenta e a sua capacidade por fita é limitada comparando com o óptico e com o disco magnético.
O capítulo 5, fez a introdução das hierarquias descrevendo os três níveis básicos : processador de registos, memória primária e memória secundária. As máquinas contemporâneas têm muitos mais níveis, incluindo memória escondida, rápido e maior armazenamento secundário e este só de leitura ( Fig. 11.2 ).
O acesso à informação armazenada no computador é feita na memória executável, que é parte da hierarquia que usa um mecanismo diferente daquele usa a memória secundária. Um processo pode aceder à memória executável com uma simples instrução de carregamento ou armazenamento em poucos ciclo de relógio. A memória secundária é implementada no carregamento de dispositivos, então o acesso envolve acção da drive e de dispositivos físicos. Por este motivo, a memória secundária tem pelo menos três ordens de grandeza com maior tempo de acesso do que a memória executável.
O gestor de memória é necessário para atribuir porções de memória executável e para providenciar mecanismos para mover manualmente dados pela hierarquia. Um sistema de memória automatiza o movimento de informação entre as memórias secundária e primária e entre memória escondida e primária. O gestor de ficheiros providencia mecanismos para administrar a memória secundária de acordo com as necessidades dos utilizadores. Este capítulo discute a gerência de memória básica. Os dois próximos discutem memória virtual e gerência de ficheiros. O primeiro passo na gerência de memória é construir o processo de espaço de endereçamento para armazenar localizações, discutido na próxima subsecção.
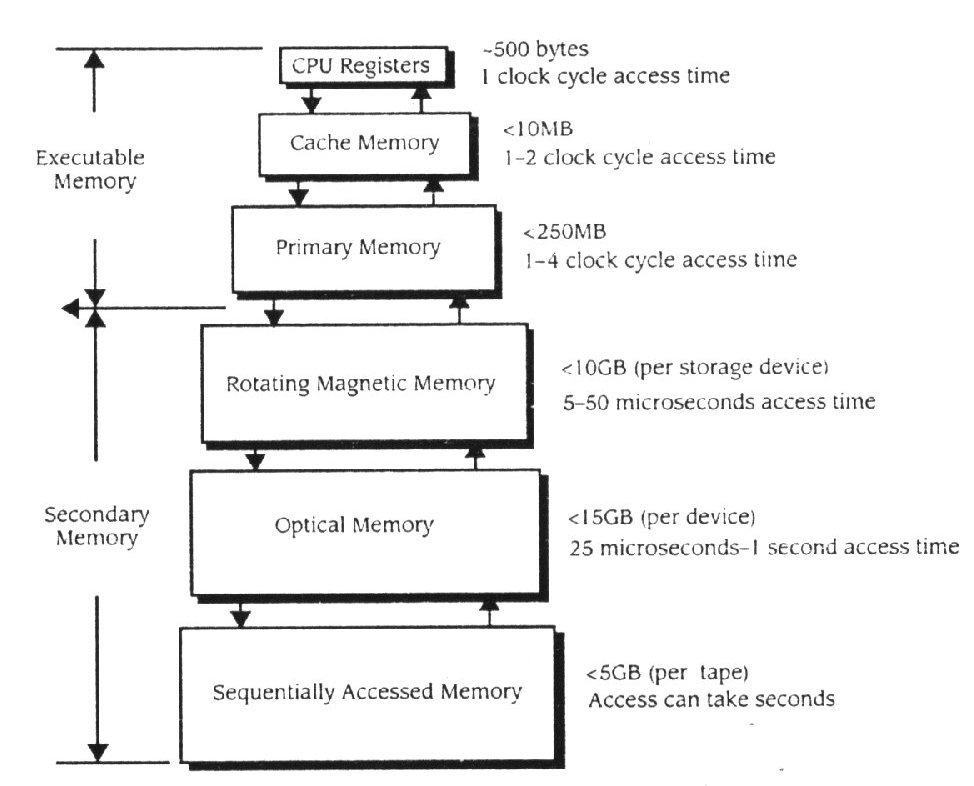
Figura 11.2
Hierarquias de memória
11.1.2 – Fazer um mapa do espaço de endereçamento para a memória primária
Um programador vê um sistema em termos de linguagem de programação e velocidade do interface. O capítulo 6 explica como um programa é traduzido por uma fonte de código dentro de um programa para um espaço de endereçamento abstracto, preparado para ser carregado e executado. Num ambiente de programa compilado, a fonte que traduz o programa fá-lo em tempo compilado, para relocalizar o programa modelo. Um conjunto de modelos de reinstalação é combinado usando um editor de ligação com o tempo de ligação para produzir um modelo absoluto (ou carregado), desta forma definindo a parte do espaço de endereçamento para instruções, dados, e empilhamento. Quando o modelo absoluto estiver preparado, o editor de ligação determinará a organização interna do espaço de endereçamento. Geralmente com tudo, não se sabe ao certo a localização na memória primária onde esse espaço irá ser carregado, com isto não se consegue prender os endereços na instrução para a memória física de endereços. O modelo absoluto é construído como se fosse carregado e executado na localização de memória 0. O carregamento modifica o endereçamento, no modo e tempo de carregamento, para produzir a imagem executável armazenada na memória primária. Na construção de um entendimento dos fundamentos da gestão de memória, você precisa de considerar a gestão e endereços durante várias fazes da tradução do processo.
11.1.2.1 – Tempo compilado
Considere uma variável estática no programa fonte. Uma variável estática é uma variável que retém o último valor armazenado, mesmo que saia fora do alcance. No tempo compilado, o tradutor gera um código para atribuir armazenamento à variável e depois usa o endereço do armazenamento, qualquer que seja o código de referencia da variável. Desde que a variável seja estática, o seu espaço está no segmento de dados do programa. Se for uma variável automática c, será no tempo decorrido no armazenamento. A organização do segmento de dados para o programa, não será conhecida, enquanto a relocalização modelo é combinada com outras no tempo de ligação, portanto o compilador prende o endereço da variável num conjunto de endereços começado no 0. Este conjunto vai ser combinado com outros conjuntos, por intermédio do editor de ligações para fazer aparecer os segmentos de dados.
A seguir, considere o procedimento de um ponto de entrada. Em geral, o compilador não será capaz de determinar o endereço para o ponto de entrada, desde que o objectivo esteja dentro de um modelo diferente de relocalização. Por exemplo, se o objectivo for uma rotina de biblioteca, como o print f, terá de ser compilado quando o software do sistema for construído. Desde que o endereço do objectivo não seja conhecido no tempo compilado, não pode ser limitado ao tempo compilado. Em vês de ser trabalhado no tempo de ligação. O compilador irá anotar cada referencia para um endereço externo, de forma a que o editor de ligação ponha o endereço correcto no código.
11.1.2.2 – Tempo de ligação
No tempo de ligação, os vários segmentos de dados gerados pelo tradutor e escritos para o modelo de localização, são combinados para formar um só segmento de dados. O editor de localização relocaliza os endereços nas instruções que referenciam o segmento de dados e os pontos de entrada exteriores, alterando todas as referencias de forma a que apontem para a correcta localização no modelo absoluto.
11.1.2.3 – Tempo de carregamento
No tempo de carregamento, os endereços têm de ser ajustados mais uma vez. Para simplificar, todos os endereços no modelo absoluto são justificados como se o modelo fosse carregado na localização física 0. Contudo, o modelo pode eventualmente ser carregado em qualquer sítio da memória executável, dependendo do estado da memória e da estratégia empregada pelo gestor de memória. O carregador determina a actual localização onde a imagem programada é carregada, isso prende os endereços ao programa numa localização de memória física que contém as respectivas variáveis ou instruções.
11.1.3 – Memória dinâmica para estruturas de dados
Linguagens de programação, muitas vezes definem uma facilidade em permitir que um programa dirija parte do seu espaço de dados, se bem que a linguagem não define como é feita a atribuição de memória nem como a ligação deve ser feita. Do ponto de vista do programador, esta facilidade é usada para suportar solicitações dinâmicas de espaço, para armazenar estruturas de dados ( para implementar listas, organizações em árvore, strings, e etc.). Desde que esta facilidade seja para si a primeira introdução à atribuição de memória dinâmica, é natural que você espere que isto seja geralmente um interface para o gestor de memória. Contudo, estes atribuidores no tempo decorrido de memória dinâmica, não criam memória para ser atribuída ao processo de maneira nenhuma. Em vez de isso, permitem que o programador ligue manualmente partes não usadas dos processos de espaço de endereçamento às estruturas de dados dinâmicos. O modelo do UNIX é representante de como este tipo de memória dinâmica é trabalhada pelo sistema. Esta ideia é explicada descrevendo o funcionamento de trabalho do C/UNIX malloc.
11.2 – Atribuição de memória
Uma vez que o modelo absoluto foi criado pelo sistema de tradução de linguagem, a memória primária deve ser atribuída ao processo. Depois o espaço de endereçamento pode ser limitado ao bloco de memória primária atribuída ao processo e a imagem executável pode ser armazenada aí. Assim a ligação de endereços não pode ser completada enquanto o espaço de memória física está a ser atribuída ao processo. O gestor de memória de um sistema operativo multi- programado aguenta a atribuição de memória primária baseado na distribuição de um espaço multiplexado. Quando um processo é construído para correr, requer espaço de memória primária ao gestor de memória, prepara o seu programa ( espaço de endereços ) para a execução, e então armazena-o na memória. A preparação do programa pode incluir a compilação, a ligação da fonte de código ou só o carregamento e a execução de programas previamente ligados.
Suponhamos que o sistema operativo suporta quatro maneiras de fazer multi - programação. O gestor de memória parte a memória em quatro blocos e depois atribui cada bloco a um processo. A figura 11.8 ilustra um instante da memória primária onde aos quatro processos foram atribuídas várias partes da memória. Desde que o sistema operativo tenha o seu espaço de memória para código e tabelas, há cinco blocos diferentes na figura. O sistema operativo está a usar memória da localização 0 para A, a memória entre a localização A e B não é atribuída, ao Process 1 foi atribuída memória entre as localizações B e C, o Process 3 foi atribuído entre as localizações C e D, à localização entre D e E não foi atribuído processo, e assim em diante.
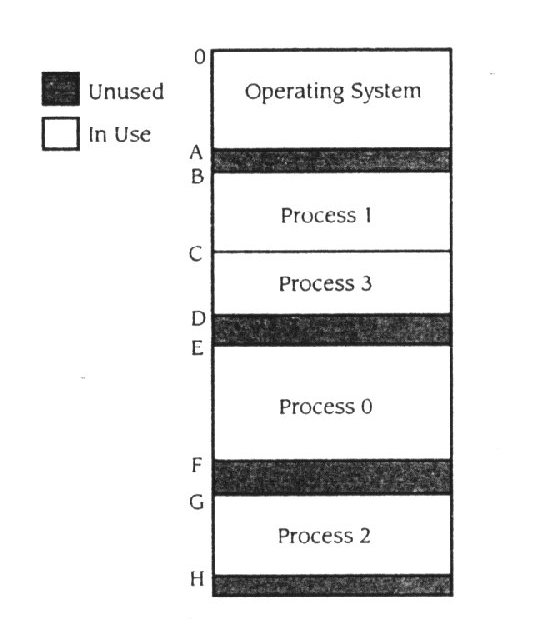
Figura 11.8
Suporte de memória multi - programada
São usadas muitas estratégias diferentes para atribuir memória. Estas estratégias são geralmente separadas de forma a dividirem a memória primária num número e tamanho fixo de blocos, no momento em que o sistema operativo é configurado e da forma dinamicamente determinada( blocos de tamanho variável). O problema básico a ser superado na atribuição de memória é a fragmentação. Idealmente, o gestor de memória pode atribuir cada byte de memória a um processo, se qualquer processo precisar de memória. Na prática, partes de memória não podem ser usadas em qualquer momento, porque o gestor de memória não é capaz de atribuir essas partes de maneira eficiente. Como é que a fragmentação ocorre, é discutido nas duas estratégias básicas.
11.2.1 – Estratégia de memória de partição fixa
Suponha que a memória primária é estatisticamente dividida em N regiões de tamanho fixo ou partições, onde Ri tem Ni unidades de memória. Tipicamente Ni ¹ N j ( as partições têm diferentes áreas ) , então processos com um espaço de endereçamento pequeno usa pequenas partições e processos com espaço de endereçamento grande usa partições grandes. A atribuição de memória num sistema de partição fixa, requer que o tamanho dos processos de espaço de endereçamento e das suas partições correspondam. Por exemplo, se um processo requer n k unidades de memória, pode ser carregado em qualquer R i , onde N i ³ n k . Sobre a atribuição de R i no processo, N i – n k unidades de memória primária, não são usadas enquanto o processo está a ser carregado, desde que o espaço seja atribuído no processo mas não faça parte do seu espaço de endereçamento. Este fenómeno é chamado fragmentação interna. Esta forma de fragmentação, faz com que haja perda de parte da memória, esperada na atribuição de N i localizações de memória, quando o processo só precisa de n k unidades. Se a memória mostrada na figura 11.8 for baseada em partições fixas, R o pode estender-se da localização 0 à B, R 1 da B à C, R2 da C à E, R3 da E à G e R4 da G até ao último endereço de memória. Desta maneira a memória da localização A à localização B é um fragmento interno não usado em R0 , a memória da localização D à E é um fragmento de memória não usado em R2 , e assim por diante. No exemplo, não há perdas esperadas na fragmentação interna em R1.
Como deve a atribuição de memória trabalhar para a partição fixa de memória? Suponha que cada região de memória tem a sua fila de processos competindo pela partição. Quando um processo requer n k unidades de memória, o atribuidor espaça os processo em fila para uma Ri , onde Ni ³ n k . Normalmente, o atribuidor seleccionará a Ri que melhor caberá em n k , ou seja, seleccionará a Ri onde Ni –n k seja minimizado. Às vezes, o atribuidor pode não usar a melhor estratégia de encaixe se algumas regiões ficarem com filas sobrecarregadas. Em vez disso, ele pode escolher qualquer região grande o suficiente para aguentar o processo. Contudo, fazer isto pode incorrer em mais fragmentações internas que a melhor abordagem de encaixe, em vez de aliviar a competição pela partição com um melhor encaixe. Outra alternativa é o atribuidor manter uma única fila com todos os processos, em seguida atribuir de acordo com a utilização.
Uma vez que um processo seja atribuído a uma região e comece a correr o programa, a carga liga o programa absoluto, para produzir um programa executável com endereços determinados pela região física de localização de memória primária. Mesmo que o gestor de memória escolha remover o processo da memória, pode salvar a imagem da memória primária na secundária e em seguida recarregar- la na mesma partição mais tarde sem reajustar os endereços.
Gestores de partição fixa de memória são extremamente usados em muitos sistemas multi - programados, mas são geralmente inconvenientes para usar em qualquer sistema em que n k não seja conhecido posteriormente ( por exemplo: sistemas de timesharing ). A memória exige dos utilizadores interactivos uma variação violenta, dependendo da actividade de qualquer terminal interactivo do utilizador. Por exemplo: o utilizador pode estar ligado à máquina, mas não usar o terminal por uma hora ou duas. Portanto, efectivamente o processo quase não precisa de memória até que o utilizador volte ao terminal e novamente interaja com o sistema. Noutros tempos, o utilizador podia estar a compilar um programa ou a formatar um documento de texto. Estes programas requerem quantidades relativamente grandes de memória comparando com a quantidade de memória que é utilizada por um editor de texto ou sistema de mail. Necessariamente, sistemas de timesharing forçam os sistemas operativos a afastar-se das estratégias de partição fixa para ambientes dinâmicos que usam melhor a memória.
11.2.2 – Estratégias de memória de partição variável
As perdas por fragmentação interna são agravadas por timesharing ,que é normalmente usado para uma forte variação num processo de memória necessário durante uma sessão de login. A forma obvia para endereçar estas perdas é redesenhar o gestor de memória, de forma a que a atribuição de regiões esteja de acordo com espaço necessário para um processo em qualquer momento. Esta abordagem efectivamente remove a possibilidade de fragmentação interna ( Nota: o atribuidor irá atribuir só multi - palavras de fronteira como um bloco de 100-bytes. Se um processo pedir uma quantidade de memória com um incremento diferente do múltiplo do tamanho mínimo, pequenas quantidades iram resultar da fragmentação interna. Estas perdas são inconsequentes comparado com o tamanho de fragmentações internas na partição fixa de memória planeada).
11.2.2.1 – A estratégia básica
O novo desafio para o gestor de memória é manter-se no caminho dos tamanhos variáveis de blocos de memória e atribui-los eficientemente. Quando o sistema for inicializado, a memória primária é configurada como um grande bloco de N0 unidades de memória ( fig.11.9a ). A tabela atribui memória, n i
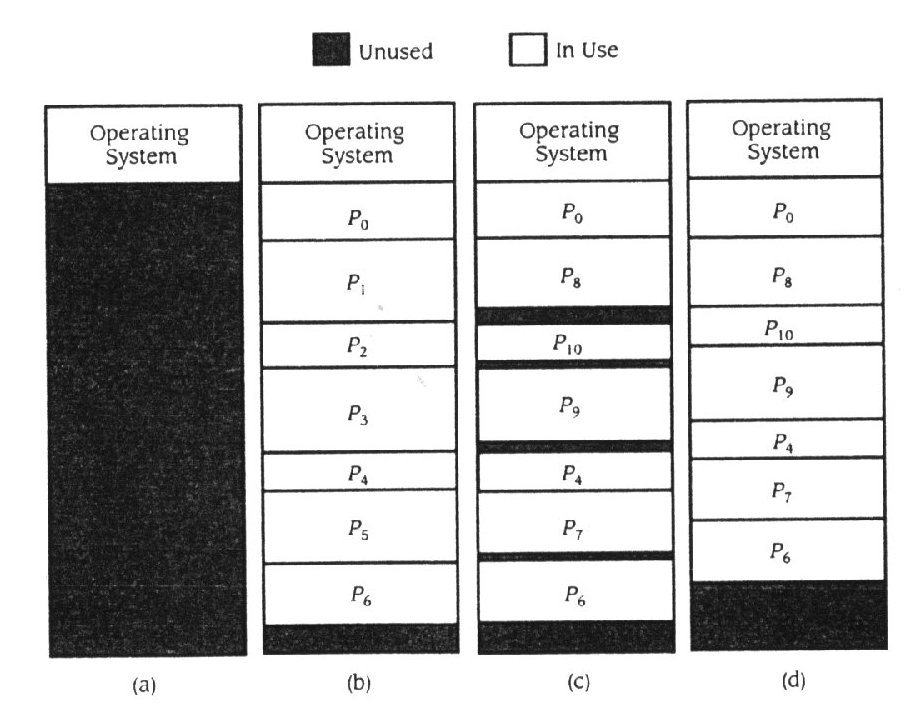
Figura 11.9
Atribuição de memória dinâmica na partição variável de memória
unidades ao processo p i , enquanto S i = 0 n i £ N0 ( fig. 11.9b ). Uma pequena quantidade de memória do fundo do espaço de memória será perdida por fragmentação externa - a parte da memória não marcada como atribuída ao sistema operativo ou a qualquer p i . Quando não houver mais processos de atribuição de memória, o gestor de memória espera pelo processo para libertar memória. Na fig. 11.9c, p 5 libertou a sua memória e p 7 atribuiu n 7 £ n 5 unidades de memória. O gestor de memória selecciona um processo " apropriado " na unidade n 5 , " aguenta " na memória esse resultado de p 5 e solta a sua memória. Por causa de variar as necessidades de memória, é possível que n 7 < n 5 , daí resulte a criação de um pequeno bloco de memória não usada entre o espaço atribuído a p 7 e p 6 . Este bloco não usado é outra consequência da fragmentação externa.
Quando p 6 libertar a sua memória, a unidade n 6 de memória é libertada conjuntamente com o espaço não atribuindo que segue p 6 . O gestor de memória deve manter uma linha de buracos, de forma a que quando aparecerem dois buracos seguidos, possam ser misturados a um grande bloco de memória não atribuída. Na fig. 11.9c , p 8 foi atribuído a um bloco previamente atribuído a p 1 , p 10 para o bloco previamente ocupado por p 2 , p 9 para o bloco previamente atribuído a p 3 e p 7 para p 5 . Esta nova atribuição criou severos fragmentos externos similarmente com os fragmentos externos originais do fundo da memória na fig. 11.9b.
Como o sistema continua a correr, as chances de fragmentação externa aumentam. Esta situação ocorre porque um processo pode caber num buraco tão grande quanto a sua memória requer. A memória extra cria uma pequena fragmentação. Mais adiante, como a memória começa a fragmentar-se cada vez mais, o gestor de memória tenderá a favorecer processos que tenham menores exigências de memória, assim causando fragmentos, em vez de se tornarem cada vez menores. Eventualmente, o sistema irá atingir um estado que só os acessos à memória mais pequena podem ser satisfeitos, mesmo quando é suficiente a quantidade de memória, para encontrar requisitos de grande solicitação. Neste ponto, o sistema operativo terá de compactar a memória, movendo todos os carregamentos de processos de forma a que use espaços contínuos na memória, assim criando um grande bloco livre ( fig. 11.9d ).
Desempenho de sintonização
O custo de mover programas
A compactação requer que um programa seja movido de um bloco de memória para outro. Isto, requer que o programa seja relocalizado, desde que as ligações de endereços que usam o carregamento, quando o programa foi carregado na primeira localização, não sejam mais validas quando for carregado numa localização diferente. Infelizmente, o carregamento só é capaz de relocalizar imagens absolutas. Isto acontece porque a imagem absoluta( por exemplo: fig.11.5 ) é feita de forma a que o carregamento possa facilmente identificar quer endereços por flags deixadas no código pelo compilador, quer o editor de ligações. Estas flags são removidas pela carga absoluta quando isso cria uma imagem executável, desde que esta imagem seja para ser interpretada, pela unidade de controlo, codificada e executada ( como foi discutido no capítulo 4 ). Portanto, quando o programa é movido, o carregamento deve começar com a imagem absoluta criada pelo editor de ligações, o que é preferível do que usar uma imagem executável carregada na memória primária( fig. 11.10 ). Qualquer alteração no processo pode fazer com que os dados, antes do espaço de endereçamento ser alterado, estejam perdidos, a não ser que tenham sido guardados na memória secundária.
Há uma solução melhor para o problema: ter o sistema alterado a maneira de ligar os endereços da localização da memória primária. Esta abordagem é explicada na secção 11.3 - descrição de como a memória não usada é gerida.
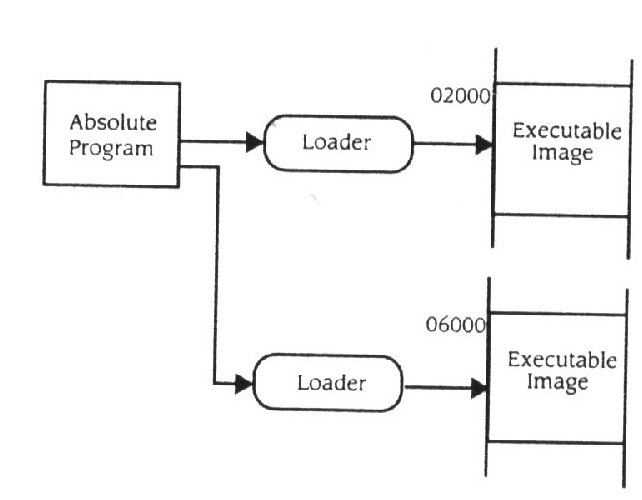
Figura 11.10
Mover uma imagem executável
11.2.2.2 – Atribuição dinâmica
Existe uma outra perspectiva que deve ser considerada na partição variável de memória. O sistema pode permitir que um processo altere a quantidade de memória atribuída enquanto é executada, dependendo da sua fase de computação. Esta perspectiva quer dizer que ás vezes o processo pode requerer mais memória do que aquela que pode caber no espaço corrente mais o espaço livre do buraco. Por exemplo, na figura 11.9c, suponha que p9 requer memória adicional numa quantidade que excede o seu espaço corrente mais o espaço livre dos buracos, por baixo disso. Como é que o pedido será realizado? O gestor de memória pode utilizar o bloco p9 até que mais espaço livre esteja disponível. Mas esta estratégia não é favorável aos utilizadores interactivos, porque eles podem incorrer em longas esperas pelo serviço. Como alternativa, o processo pode encontrar um buraco maior e mover o processo para um novo buraco, com isto libertando o velho espaço. Contudo ( como no caso da partição ), o sistema irá ter um ajustamento nos endereços do programa quando mover o espaço de endereçamento.
Num ambiente que suporta a atribuição de memória dinâmica, o gestor de memória deve ter gravado a utilização de cada bloco de atribuição da memória. Esta gravação pode ser mantida usando qualquer estrutura de dados que implemente uma lista de ligações. Uma implementação obvia é definir uma lista de descrição de blocos, com cada descrição contendo um ponteiro para a descrição seguinte, um apontador para o bloco, e o comprimento do bloco ( fig. 11.11 ). O gestor de memória guarda uma lista de ponteiros e insere entradas nessa lista com uma ordem concordante com a sua estratégia de atribuição; a figura simplesmente ordena os blocos por ordem crescente de endereços de memória primária. A memória é normalmente atribuída em blocos de múltiplas palavras, com 64 ou mais palavras por bloco. Um bloco de memória livre não é usada, o que quer dizer que o seu conteúdo não é usado por nenhum processo. Desta forma as estratégias de atribuição de memória usam normalmente poucas palavras iniciais em qualquer bloco livre para implementar a lista de ligações mostrada na figura 11.11. A lista de ponteiros aponta primeiro para a primeira localização do primeiro bloco livre.
Figura 11.11
Gerir blocos de memória livre
Existem várias estratégias diferentes para atribuir espaços ao processo que está a competir por memória. Aqui está uma breve explicação das mais populares:
11.2.3 – Estratégias de atribuição contemporâneas
Os gestores de memória modernos, usam geralmente uma forma de partição variável. Contudo, a memória é normalmente atribuída em blocos de tamanho fixo ( chamadas " páginas ", como poderá ver quando a memória virtual for introduzida na secção 11.4 ), isto simplifica muito a gestão da lista livre. Neste caso, todas as unidades atribuídas são do mesmo tamanho, de forma que a gestão da lista livre é trivial. Nos sistemas antigos, como o DOS e a versão 7 do UNIX, o gestor de memória, lidava com blocos de memória de tamanho variável. Quando um processo é criado, o gestor de memória usa a estratégia do melhor encaixe para assegurar uma inicial quantidade de memória. O processo executa, requer e liberta memória de acordo com as suas necessidades para qualquer fase da execução.
A parte do espaço de endereçamento é provável que vá alterar o conteúdo dos seus dados. Isto é porque a parte do espaço de endereçamento que contém o programa foi carregado na memória, e normalmente não vai alterar o tamanho ( uma alteração no tamanho pode querer dizer que o programa foi alterado). Todavia, supõe-se que a parte do espaço de endereçamento que contém o programa não aumenta ( nem diminui). Depois cada parte do programa está a ser descarregada na memória ou o programa é de alguma forma crescente. Em linguagens como o c, isto normalmente não é possível, contudo pode ocorrer em linguagens como o Lisp. Por outro lado, cada vez que um programa aumenta ou diminui, o carregamento deve religar cada endereço no programa na localização de memória primaria. ( Isto também acontece cada vez que um programa é mexido; por exemplo, por compactação ou por não carregamento e no recarregamento do espaço de endereçamento da memória primária).
A secção 11.1.3 explica como segurar o aumento e diminuição da parte do espaço de endereçamento que contém os dados. Neste caso, o gestor de memória aceita o pedido de mais memória para o processo ( por exemplo: como um sistema sbrk chama em BSD UNIX ( Leffer, et al., 1989 )). Vai atribuir memória para a lista livre como faz com o pedido original quando o processo já começou. Ajustando as ligações de endereços por dados, pode ser mais fácil que por programas, desde que os dados não necessitem de ter endereços relocalizados. Por exemplo: no sistema UNIX sbrk chamar a memória é adicionar ao espaço de endereçamento o intervalo de endereçamento. Neste caso, a memória dos endereços não precisa de ser ajustada.
Em conjunto com a memória de tamanho variável, os sistemas operativos modernos, sistema de translação de sistemas, e hardwear combinam-se para iniciar uma nova abordagem da ligação ao espaço de endereçamento. A finalidade é promover uma alternativa ao uso de carregamento para ligar endereços.
11.3 - Relocalização de endereço dinâmicos
Tradicionalmente, os símbolos de um programa fonte são primeiro limitados a endereços relativos num modelo de relocalização em tempo compilado, depois endereçados num modelo absoluto no momento de ligação, e finalmente endereços de memória no momento de carregamento. Todos os endereços são ligados a localizações prévias de memória em tempo decorrido. Como se descreveu em secção 11.1, sistemas de programação de linguagem em tempo decorrido providenciam uma facilidade de ligações, com atribuições facilitadas de memória dinâmica para apoiar estruturas de dados dinâmicas. No UNIX malloc call, o programador liga manualmente endereços usando o ponteiro da linguagem de programação. Por exemplo quando um processo executa um fragmento de código como:
struct ListNode *node;
....
node = ( struct ListNode *) malloc(sizeof(struct ListNode));
....
o programa usa o ponteiro de node para referência do endereço base do bloco de memória e a estrutura de dados ListNode para referenciar campos individuais na estrutura de dados, por exemplo escrevendo nomes de variáveis como nodo->left. Recordando a discussão da implementação desta abordagem (secção 11.1.3), que esta forma de distribuição dinâmica é realizada ligando espaço não atribuído no espaço de endereçamento em vez de atribuir memória nova ao processo.
Se houvesse uma ferramenta mais geral para ligar endereços de programa absolutos no tempo decorrido, o gestor de memória teria a liberdade para mover o programa à volta da memória sem exigir que o programador entrasse em alguma acção especial para compensar a relocalização. Isto também faria uma aproximação geral dos gestores de memória usando a estratégia de partição variável. Com estas estratégias, eles poderiam mudar a memória atribuída a um processo sem a preocupação de a relocalizar de novo. Esta aproximação é chamada relocalização dinâmica.
Considere o algoritmo, o carregador usa - o para ajustar endereços no módulo absoluto de forma a que ele emparelhe os endereços físicos. Considerando que o modelo absoluto é construído como que se se carregasse a memória na localização 0, são endereços que dependem deste facto para ser relativos ao começo do módulo. (Programas podem ter " endereços " diferentes dos endereços compilados relativos a campos do operador. Por exemplo: um operador imediato não deveria mudar quando um módulo é relocalizado. Alguns jogos de instrução incluem um endereço compensado que significa que o operador é um compensatório dos conteúdos do PC actuais. Isto de compensar permite que um programa se ramifique para traz e para diante do número de endereços especificado pelo operador. Tais operadores são comuns em máquinas que usam operadores de endereços de16-bits.) Quando o carregador determina o endereço actual da primeira localização no modelo, pode ajustar qualquer endereço relativo somando o valor da primeira localização. Na figura 11.6, cada endereço relativo do modelo absoluto da figura 11.5 teve 4000 endereços somados, isto porque o modelo foi carregado na localização 4000.
O hardware pode ser incorporado facilmente no design do processador, para executar esta relocalização em cada referência à memória. Usando o hardware permite-nos que a última fase de relocalização seja adiada. Suponha que o CPU ignora a relocalização e simplesmente começa a executar o programa. Cada endereço a ser localizado de novo iria indicar à memória que era um endereço de memória. O hardware interceptaria esse endereço e somaria um valor de relocalização para enviar à memória (figura 11.12).
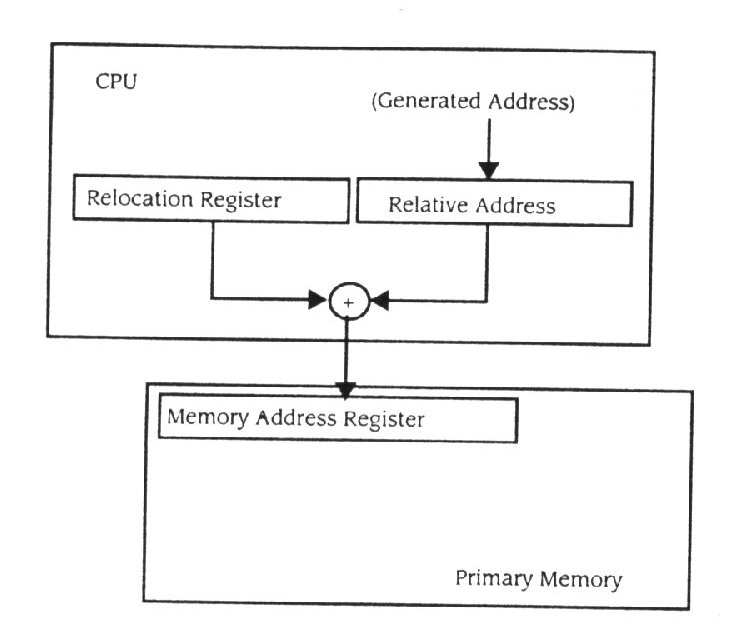
Figura 11.12
Relocalização de endereços em hardware
O registo de relocalização é parte do estado do processo, desta forma ele será alterado cada vez que um processo diferente for atribuído ao CPU. Esta habilidade causa uma imagem executável para ser produzida no momento de carga, mas com a suposição de que todos os endereços enviam à memória primária o conteúdo de registro de relocalização somado a isso. Este hardware de relocalização dinâmica é normalmente usado em processadores contemporâneos, independente de qualquer estratégia de administração de memória adicional. Isto dá ao sistema operativo uma grande liberdade no que diz respeito à localização, na qual imagens executáveis são carregadas na memória primária sempre que o gestor de memória precisa de mover programas no meio da sua execução.
Compiladores contemporâneos tiram proveito da relocalização do hardware. Eles são projectados para gerar dados e codificar em segmentos distintos dentro de um modelo de relocalização. Por exemplo, programas em C são compilados num segmento de texto que contém o código, num segmento de pilha que contém variáveis temporárias, e num segmento de dados que contém variáveis estáticas. O processo modelo UNIX (como se descreveu no Capítulo 3) é modelado depois do programa de modulação. Para providenciar o suporte explícito para tal linguagem modelo, o CPU é projectado com pelo menos três registos de relocalização para gerir o código, empilhar, e para segmentos de dados como modelos de relocalização separados. O CPU contém registos de relocalização de segmento de código, de segmento de pilha e de segmento dados (Figura 11.13). O registo de segmento de código
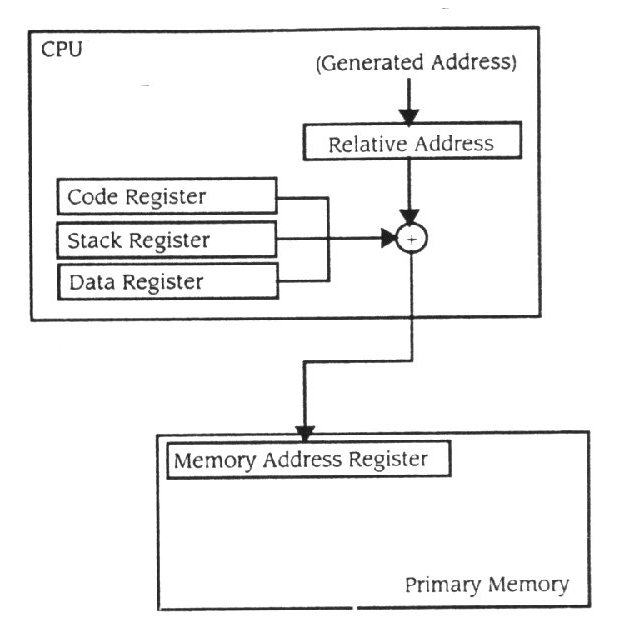
Figura 11.13
Múltiplos segmentos de registos de relocalização
relocaliza todos os endereços enquanto o processador busca o ciclo, o registo de segmento de pilha relocaliza endereços para a execução de instrução de pilha, e o registo de segmento de dados relocaliza todos os outros endereços durante a execução do ciclo.
Pode a administração de um segmento de registo ser dirigida " automaticamente " pelo sistema operacional? Suponha que o compilador gera endereços normais de 16-bit quando traduz a fonte modelo e deixa referências externas serem dirigidas pelo editor de encadeamento. Mais adiante suponha que nenhum modelo individual tem um código ou segmento de dados maior que 64KB, embora o programa absoluto resultante possa ser muito maior que 64KB. Consequentemente, todo o código gerado será de 16-bit relativo ao endereço no código ou segmentos de dados para o modelo de relocalização. Quando qualquer função é executada num modelo, o código de inicialização ao ponto de entrada carrega o código e o registo dos segmentos de dados para apontar à parte da imagem absoluta que corresponde ao modelo de relocalização. O endereço usado pelo prólogo deve ser provido pelo editor de encadeamento. Agora, quando o controlo se move de um modelo para outro, a função de chamada vai referenciar um símbolo externo que será solucionado depois pelo editor de encadeamento. O compilador reconhece este facto e gera um código para ajustar o registo de segmento de código para chamar a função externamente definida antes da instrução ser executada (figura 11.14). Cada
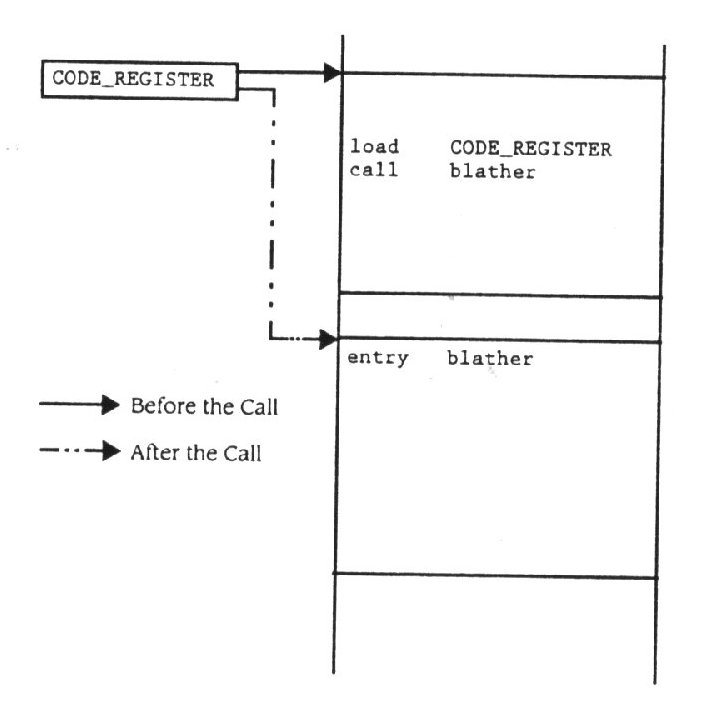
Figura 11.14
Ajustando o código de registo
chamada através de modelos causa uma mudança no registo de segmento de código. Desde que os dados de referência fora do bloco de 64KB também devam ser definidos como referências externas na fonte de código, o compilador pode reconhece - las e gerar um código para mudar o registo do segmento de dados. Cada referência a uma variável externa causa um registo de segmento de dados para mudar. Esta técnica baseia - se no compilador e no editor de encadeamento para providenciar um enorme espaço de endereçamento através da manipulação do registo de segmentos. A aproximação falha para a linguagem de programação em assembly, para qualquer programa que inadvertidamente muda um valor de registo de segmento, ou em casos em que a fonte modelo gera um código ou segmentos de dados maiores que 64KB.
Esta técnica também confia numa instrução call não comum na linguagem máquina. O que acontecerá se o compilador gerar uma instrução para fixar o código de registo numa instrução logo antes da instrução call? A próxima instrução encontrada não será a da localização que segue o segmento de registro que carrega a instrução. Preferivelmente, será uma na localização correspondente noutro segmento de 64KB. Para esta aproximação ao trabalho, deve ser possível carregar o segmento de registo e executar o call antes do segmento de registo ser actualizado em vez de executar o call numa instrução.
Máquinas com instruções privilegiadas podem ter uma abordagem ligeiramente mais sofisticada. Tal máquina não permite que o segmento de registo seja mudado excepto por uma instrução privilegiada. O compilador gera uma instrução armadilha para qualquer que seja o registro de segmento que precise de ser ajustado. No tempo decorrido, a instrução armadilha interrompe a execução de programa e começa o sistema operativo. A armadilha é conhecida como o segmento armadilha e é passada ao gestor de memória. O gestor de memória determina o endereço designado e então ajusta o contador de programa e o segmento de registo para referenciar o distante endereço designado. Também, esta técnica, exige que uma instrução seja capaz de fixar o contador de programa e o segmento de registo antes que outra instrução seja buscada da memória.
11.3.1 - Verificação limite no tempo decorrido
O registo de relocalização provou ser uma adição fundamental para sistemas de computador, desde que permita a ligação de endereço dinâmica. Uma vez que um mecanismo foi incorporado no hardware, é fácil fazer adições pequenas para um aumento substancial da habilidade do sistema em apoiar a protecção de memória. Suponha que cada registo de relocalização tem como companheiro um registo de limite, que está carregado com a duração do segmento de memória endereçado pelo registo de relocalização. Sempre que o CPU envia um endereço à memória primária, o registo de relocalização é somado ao endereço ao mesmo tempo que é comparado com os conteúdos do registo de limite (Figura 11.15). Se o endereço é menor que o valor no registo
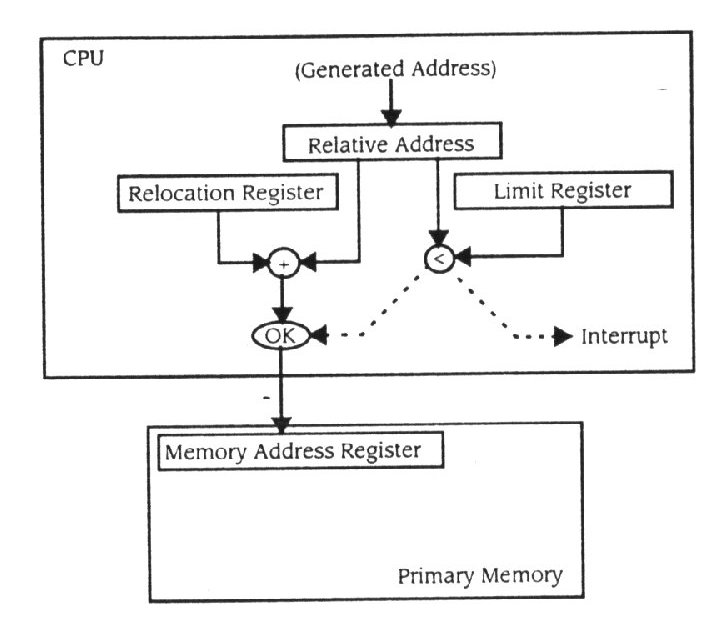
Figura 11.15
Verificação limite com um registo limite
limite, o endereço refere - se a uma localização dentro de um segmento de memória. Se o endereço é maior que o valor de registo limite, refere - se a uma parte da memória primária não atribuída ao processo que usa regularmente o CPU. Uma referência a fora dos limites também chamado segmento de violação, irá gerar uma interrupção, produzindo um erro de execução fatal.
11.4 - Estratégias do gestor de memória
A memória virtual é a estratégia de administração de memória dominante em sistemas operativos modernos, seguido pela troca em sistemas operacionais de baixa funcionalidade e em computadores com hardware de organização moderada. Trocando tecnologia foi o primeiro a tirar proveito do hardware de relocalização dinâmica. Isso influenciou o modo como a memória virtual evoluiu. Assim nós estudamos as trocas como a base para entender a memória virtual. A memória virtual é introduzida nesta secção e é coberta extensamente no Capítulo 12.
Estratégias de memória em múltipla - partição são a base da multi - programação. Dividindo a memória em regiões e atribuindo essas regiões a um processo, o programa pode multiplexar o CPU por estes processos a uma alta taxa de velocidade. Se um assume que há sempre processos prontos a executar, então a memória primária pode tornar - se o meio de desempenho. Suponha que N processos são carregados na memória primária e uns processos K adicionais poderiam correr se tivessem memória atribuída a eles. Então sempre que quaisquer dos N processos é bloqueado em I/O, ou num semáforo, ou noutra condição, a memória que o aguenta não está a ser usada para qualquer propósito útil. Nem o processo carregado, N-1, nem o processo K que está à espera podem usar a memória porque está a ser atribuída ao processo bloqueado.
11.4.1 - Swapping
Gestores de memória de swapping tentam aperfeiçoar desempenho do sistema através da remoção de um processo da memória primária quando está bloqueado, não atribuindo a memória, atribuindo - a a outros processos, e então readquirir e recarregar o processo de trocar - exterior quando o processo volta ao estado pronto. Por exemplo, quando o processo pi pede uma operação de I/O, torna – se bloqueado e não voltará ao estado pronto para um período de tempo relativamente longo. Quando o gestor de processos coloca pi num estado bloqueado, notifica o gestor de memória de forma a que ele possa decidir se troca o processo da imagem de memória primária para a memória secundária (Figura 11.16). Quando o gestor de processo move um processo
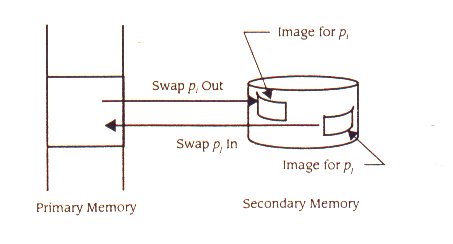
Figura 11.16
Swapping
bloqueado, pj, para o estado pronto, se pj é trocado fora, o gestor de processo informará o gestor de memória de forma a que ele possa trocar o espaço de endereço de volta à memória primária, no momento em que a memória primária estiver disponível ou pelo menos assim que fique disponível.
Quando um processo é trocado fora, a sua imagem executável é copiada para a memória secundária código, dados, e pilha. Quando é trocado de volta para a memória primária disponível, a imagem executável que foi trocada fora é copiada para um bloco novo atribuído pelo gestor de memória. Sem hardware de relocalização, swapping seria muito difícil de alcançar devido ao problema de ligação de endereços. Com hardware de relocalização, a imagem executável é copiada simplesmente na recente região atribuída de memória.
Swapping são especialmente apropriadas a sistemas de timesharing, como tal o sistema frequentemente toma notas sobre a máquina (e consequentemente está a usar alguns recursos) mas é inactivo para períodos relativamente longos de tempo (e consequentemente não usa o CPU). Um gestor de memória swapping acomoda o timesharing atribuindo memória a um processo enquanto o utilizador pede um serviço com uma velocidade relativamente alta, mas retira memória durante essas fases quando o utilizador pede um serviço a uma baixa velocidade. Isto é, num sistema de timesharing, o gestor de memória pode decidir trocar um processo fora da memória mesmo que esteja pronto, dependendo do total carregamento na máquina.
A observação chave sobre um sistema swapping é que se um processo não vai usar o CPU durante muito tempo, deveria libertar a memória atribuída. Isto permite outros processos para usar a memória e o CPU. Gestores de memória em timesharing voltam frequentemente a esta observação, adoptando a estratégia de endereçar o caso aos muitos pedidos de memória e de CPU, então haverá recursos de memória disponíveis. O gestor de memória selecciona alguns processos que são para largar memória (e o CPU) de forma a que os outros processos tenha também uma oportunidade para os usar. Os processos seleccionados são bloqueados (num pedido de memória) pelo gestor de memória e então a memória deles é retirada. Eles começam a competir com outros processos para requererem memória. Sistemas de timesharing contemporâneos (como as muitas versões do UNIX) usam o swapping para providenciarem um serviço equivalente a um sistema de timesharing subscrito em excesso. Quando o número de utilizadores activos ultrapassar o número pré definido pelo sistema, o gestor de memória começará a trocar processos.
Algumas formas da política de swapping são quase sempre pedidas com um qualquer multi - programa, ambiente de sistema interactivo, mesmo aqueles com enormes quantidades de memória física. Como a carga global na máquina é determinada por uma contínua e imprevisível actividade humana, há grandes períodos tempo em que o processo está a segurar a memória mas ela está inactiva. Contanto que não haja outros processos a ser bloqueados pelo gestor de memória, há nenhuma necessidade de troca. Com tudo, uma vez que a fila de pedidos de memória começa a crescer, o gestor de memória começa a trocar processos fora da memória sempre que eles tenham um período de inactividade que exceda um limite. Como a fila de pedidos de memória cresce, o limite pode diminuir. O efeito da troca é percebido facilmente pelo utilizador, desde que resulte num aumento notável do tempo de resposta.
Afinação de desempenho
Quando é que um processo deve ser trocado fora?
A decisão sobre trocar um processo pode depender ou do tempo que é necessário para que um processo seja bloqueado, ou da necessidade de trocar um processo num esforço para equilibrar a partilha da memória e do CPU. Observe aqueles aumentos de desempenho ganhos por swapping nunca são uma vantagem para o processo, desde que o processo tenha de competir para requerer memória primária. O ganho no desempenho é um ganho de um largo sistema comprovado, por exemplo, pela redução na média de dar a volta / resposta no tempo para um processo.
Qual é o custo de trocar fora um processo? Se um processo aguenta S unidades de memória primária, então nós podemos computar num tempo maior para copiar a imagem executável para um dispositivo de armazenamento e o tempo de o copiar de volta na memória primária quando a troca é interna. Se um bloco de disco tem D unidades de memória primária, então o gestor de memória irá precisar de escrever pelo menos R = S/D (R é arredondado ao inteiro mais alto) blocos de disco para guardar a imagem executável. Precisará de executar o mesmo número de operações lidas para trocar o espaço de endereçamento de volta na memória primária. O custo para o processo é o tempo que o processo gasta a competir para recuperar memória primária depois entrar no estado pronto enquanto está a ser trocado fora. Assim onde quer que o gestor de memória decida trocar fora um processo, o atraso no tempo ou tempo de troca, 2R, e o tempo de requerer memória é todo superado.
Suponha que o gestor do processo muda o estado de um processo aguentando S unidades de memória para bloquear e isto mantendo – se bloqueado para T unidades de tempo. O produto espaço* tempo, S x T, representa a quantidade de recursos desperdiçados devido ao processo estar bloqueado enquanto aguenta a memória. Se S for pequeno, então o gestor de memória só irá ganhar uma pequena quantidade de memória para ser usada por outros processos se trocar o processo. Se T for pequeno, então o processo começará a competir imediatamente por memória primária. Se T < R, então o processo começará logicamente a pedir memória antes de estar completamente trocado fora. Para a troca para ser efectiva, T deve ser consideravelmente maior que 2R para qualquer processo o gestor de memória escolhe - o para trocar fora e S deve ser grande o bastante para permitir que outros processos sejam executados.
O gestor de memória conhece S para todo processo, mas só pode predizer o valor de T quando um processo se tornar bloqueado. Se o processo se tornar bloqueado porque pede uma operação de I/O num dispositivo lento, então o gestor de memória pode calcular um pequeno salto em T e consequentemente em S x T. Quando um processo se torna bloqueado devido a um pedido arbitrário de recurso (por exemplo uma operação P num semáforo ou um pedido de uma série de recursos reutilizáveis), o gestor de memória não pode calcular T. Numa estratégia conservadora de swapping, um processo não será trocado por tal pedido. Mas numa estratégia optimista, o processo pode ser trocado em quase qualquer operação de pedido.
Se o gestor de memória decide trocar fora um processo devido a uma severa competição por memória, pode computar um produto diferente espaço* tempo, S x T', onde T' é a quantidade de tempo em que o processo aguentou S unidades de memória. Se S x T' for grande para algum pi e outro processo está à espera para ser trocado internamente, então o processo aguentou a memória durante muito tempo. No interesse de equilibrar a partilha, a política do gestor de memória pode ser trocar fora pi e para trocar um outro processo no espaço previamente usado pelo pi.
11.4.2 - Memória virtual
Estratégias de memória virtual permitem um processo use o CPU só quando parte de seu espaço de endereçamento está carregado na memória primária. Nesta abordagem, o espaço de endereçamento de cada processo é dividido em partes que podem ser carregadas na memória primária quando são precisos e caso contrário escritos de volta na memória secundária (figura 11.17). Os programas são escritos para naturalmente terem partições
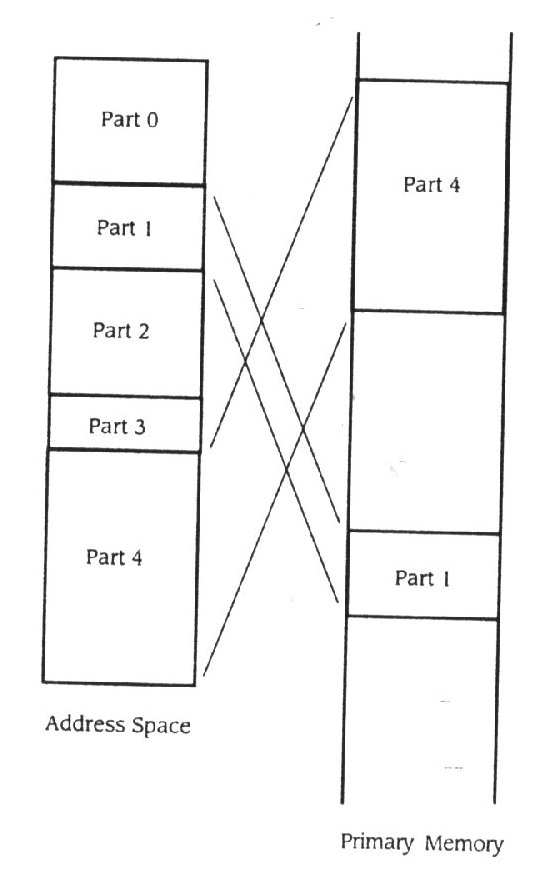
Figura 11.17
Memória física e virtual
implícitas. Partições no espaço de endereçamento foram usadas para o código, dados, e pilha identificados pelo compilador e pelo hardware de relocalização.
O segmento de código normalmente tem um jogo de partições mais subtil relativamente às fases de computação definidas pelo programa. Por exemplo, quase todos os programas têm uma fase para inicializar estruturas de dados, outra para ler os dados introduzidos, um ou mais para a actual computação (dependendo do algoritmo), outros para a recuperação do erro e informação, e um para a saída. Partições implícitas semelhantes existem normalmente no segmento de dados. Esta característica do programa chamada referência de localização espacial é muito importante para a estratégia usada por sistemas de memória virtuais. Quando um programa está a executar numa parte de seu espaço de endereçamento, a sua localização espacial é o jogo de endereços usado durante aquela fase da computação. Como a computação se move para uma fase diferente (referenciando partes diferentes do espaço de endereçamento para o programa e/ou dados), isso muda a localização.
Na figura 11.17, o espaço de endereçamento é dividido em cinco partes. Porém, só as partes 1 e 4 é que abarcam a parte do espaço de endereçamento que o programa está a usar no momento em que o estado de memória é observado; então só as partes 1 e 4 é que são carregadas na memória primária. Diferentes partes do programa serão carregadas em momentos diferentes, dependendo da localização do processo. A tarefa do gestor de memória virtual é deduzir a localização do programa e manter a parte correspondente do espaço de endereçamento carregada na memória primária enquanto o processo está o está a usar.
Um gestor de memória virtual atribui porções da memória primária que são do mesmo tamanho das partições no espaço de endereçamento e então carrega a imagem executável para a parte correspondente do espaço de endereçamento na memória primária atribuída. O efeito é que o processo usa muito menos memória primária, assim aumenta muito a memória disponível para outros processos. Suponha o gestor de memória virtual poderia ser projectado " perfeitamente ". Quer dizer, sempre soube o jogo exacto de endereços no local do programa e sempre manteve exactamente essas partes do espaço de endereçamento carregadas na memória primária antes de eles serem referenciados (e descarregados quando eles já não fizerem parte do local). Então nem sequer o processo não pôde detectar que não tinha uma memória primária atribuída tão grande quanto seu espaço de endereçamento.
Que barreiras devem ser superadas para implementar a memória virtual? O gestor de memória deve poder tratar o espaço de endereçamento em partes que correspondem aos vários locais que existirão durante a execução do programa. O sistema deve poder carregar uma parte em qualquer lugar na memória física e dinamicamente ligar os endereços na parte para a localização física na qual eles estão carregados. A quantidade de memória atribuída ao processo pode variar, em muitas partes, ou só no mínimo, pode ser carregado imediatamente. O próximo capítulo endereça estes assuntos.
Memória virtual começou a aparecer nas máquinas comerciais nos anos setenta. Naquele tempo, os custos da memória primária eram altos, assim a quantidade de memória na máquina limitou o seu uso. A memória virtual ofereceu um modelo de processos para executar usando um espaço de memória primária que era menor que seu espaço de endereçamento. Isto permitiu aos projectistas de sistemas que usassem regiões de memória relativamente pequenas com graus mais altos de multi - programação. Por exemplo, uma máquina com 256KB de memória poderia suportar oito modos de multi – programação com memória virtual mas só quatro é que usam outras regiões de tamanho variável. A motivação para memória virtual era superar limitações de tamanho de memória com custo efectivo das configurações de memória. Como se mostrou na anterior Afinação de Desempenho, gestores de memória virtuais contemporâneos também tentam usar as hierarquias de memória em conjunto com técnicas de memória virtuais para reduzir o tempo de execução de um processo reduzindo os atrasos no acesso à memória. Considerando que a justificação original foi motivada através de custos da memória, a motivação em sistemas operativos modernos é uma combinação de custo e do desempenho.
Afinação de desempenho
Usando a memória cache
Como foi discutido na Secção 11.1, computadores contemporâneos empregam frequentemente uma memória cache para aumentar o desempenho do computador. Uma memória cache tem uma alta velocidade de memória localizada no seguimento de dados entre o processador e as interligações na Net (figura 11.18) .Na figura 11.18 (a), quando o processador referência uma
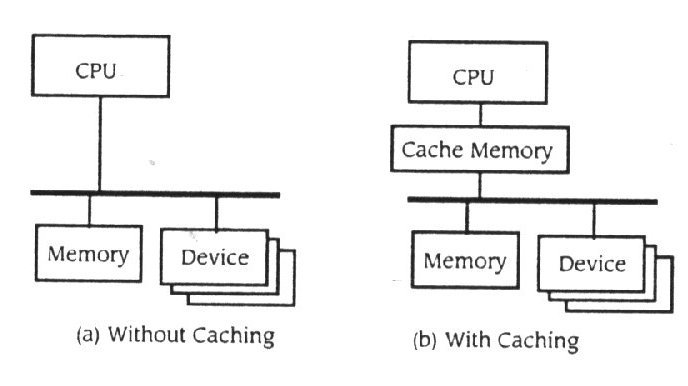
Figura 11.18
Memória cache
unidade da memória primária o CPU tem de competir com todos os dispositivos para o uso do bus. Isto frequentemente causa no CPU uma espera enquanto um dispositivo termina seu acesso. Usando os princípios de memória virtual, os fabricantes podem projectar hardware para incorporar uma memória cache entre o CPU e o sistema de bus. Nesta abordagem, sempre que o CPU tem acesso a memória, uma cópia da informação tida nesse acesso é colocada na memória cache. Da próxima vez o processador referencia a mesma localização de memória, o valor pode ser achado na memória cache, assim o processador não necessita de usa o bus para referenciar a cópia mantida na memória.
Conforme as partes são copiadas da memória secundária para a memória primária num sistema de memória virtual, num sistema caching com linhas cache é copiado da memória primária na cache. Na maioria da estratégia cache é implementada no hardware em vez de ser uniformemente dividida entre o hardware e o software, como na memória virtual normal. O gestor de memória para um sistema operativo faz algumas compensações para a presença de caching.
O uso de uma memória cache pode afectar o desempenho profundamente, dependendo da natureza dos padrões de acesso à memória do CPU e da estratégia usada pelo gestor da cache. No pior caso, o seu uso não traz nenhuma melhoria, desde que o custo alto domina o tempo de acesso. No melhor caso, o tempo de acesso à memória efectiva pode ser reduzido por um factor de dois ou três.
11.4.3 – Partilhar a memória dos Multiprocessadores
Foram estudados Multiprocessadores durante várias décadas, mas nos anos oitenta, eles amadureceram como computadores comerciais viáveis. Alguns multiprocessadores partem da arquitectura de Von Neumann num esforço aumentar velocidades fundamentais do processo, mas a maioria adapta a arquitectura básica de Von Neumann para cada processador no multiprocessador. Duas classes gerais do multiprocessador evoluíram: máquinas de distribuição de memória e máquinas de partilhar memória [Hwang e Briggs, 1984]. Naturalmente, arquitectura do computador continua a evoluir, com novos multiprocessadores que combinam aspectos de Hwang e caracterizações de Briggs. Os estudantes de arquitectura do computador são encorajados a consultarem a literatura actual, como os procedimentos da conferência sobre a arquitectura do computador [IEEE] ou o IEEE/ACM conferência de ASPLOS anual [IEEE/ACM], para ver estes novos e excitantes desenvolvimentos. A discussão aqui é limitada sobre a distribuição de memória e organizações de memória partilhada, desde que estes ilustrem as extensões para a gestão de memória necessária para esta classe de máquinas.
As máquinas de memória distribuída são logicamente equivalentes à network nisso eles confiam em passar mensagem para compartilhar informação através de processadores. A gestão de memória nestes máquinas, e na rede de máquinas, é normalmente um tópico de pesquisa no estudo de sistemas operativos. Basta dizer que apesar do facto de que a informação poder ser movida fisicamente entre memórias só usando a mensagem passe, os sistemas operativos para estas máquinas podem ir para grandes durações para providenciar uma interface de memória partilhada para a aplicação do software(Secção 17.4).
Esta secção foca a memória partilhada com multiprocessadores. Uma máquina de memória partilhada toma em geral a forma descrita na figura 11.19.
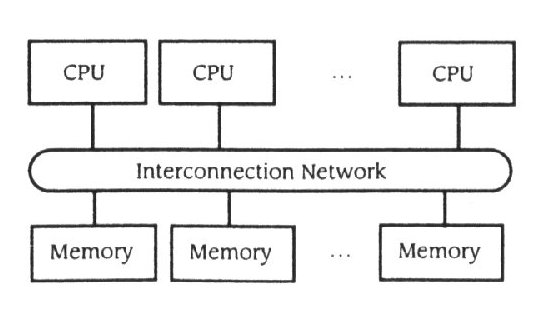
Figura 11.19
Arquitectura de memória partilhada
Vários processadores partilham uma interligação na rede (frequentemente, só um bus) para ter acesso a um jogo de modelos de memória partilhada. O mecanismo de endereçamento de hardware permite ao software em qualquer processador ter acesso qualquer localização de memória em qualquer unidade de memória na interligação da rede. A tendência em partilhar a memória dos multiprocessadores é para empregar fora dos microprocessador como o engenho do processador, para incorporar uma sofisticada interligação da rede(ICN)- este componente é a via para o desempenho em máquina de memória partilhada - e para usar unidades de memória industrialmente standarizadas e dispositivos. A maioria dos sistemas operativos para máquinas de memória partilhada são adaptações feitas pelo UNIX, onde as mudanças providenciam um sistema de chamada de extensão de interface para manipular os endereços de memória de forma a que as localizações de memória correspondentes possam ser partilhadas.
O objectivo da partilhar a memória do multiprocessador é de usar processos ou meios para implementar unidades de computação onde a informação é partilhada por localizações comuns de memória primária. A tradução do software cria uma barreira providenciando que cada processo tenha o seu próprio espaço de endereço isolado (figura 11.20). No Processo 1
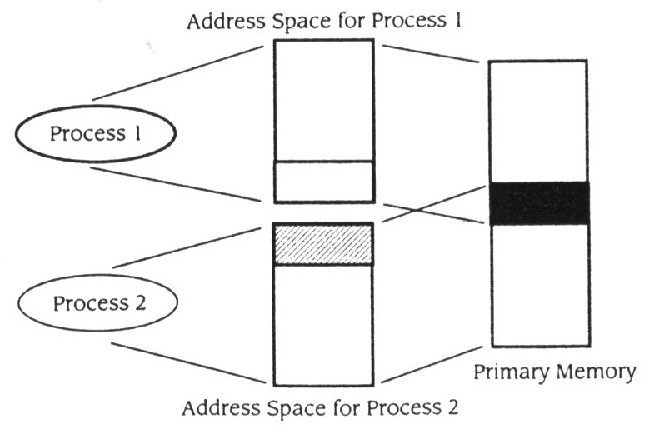
Figura 11.20
Partilhar uma partição do espaço de endereçamento
o espaço de endereçamento foi disposto de forma a que o último " bloco " do espaço de endereçamento seja para ser localizado na memória primária partilhada. No Processo 2, o primeiro bloco, que é do mesmo tamanho que o último bloco do Processo 1 do espaço de endereçamento, é para ser localizado nas mesmas localizações da memória primária. Quando os programas são carregados ao mesmo tempo, as partes dos dois espaços de endereçamento independentes do mapa partilham o bloco comum. Quando o processo 1 escreve uma variável na memória, o Processo 2 pode ler seu valor. Esta técnica resulta em desempenho muito elaborado.
Na figura 11.21, são usados pares de registro de relocalização limite
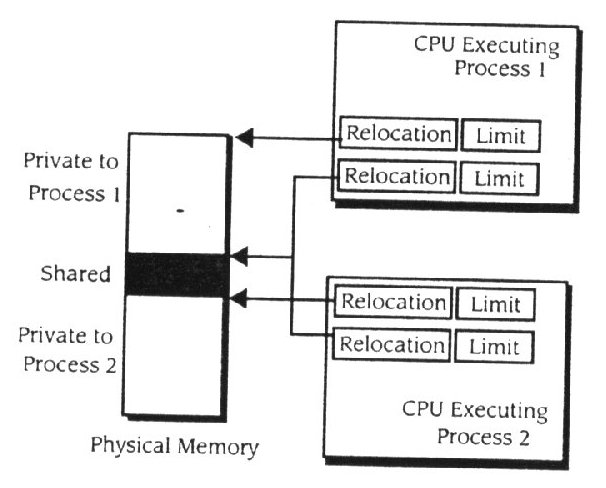
Figura 11.21
Segmentos múltiplos
múltipla para suportar o bloco partilhado. O espaço de endereçamento é separado numa parte privada e numa parte partilhada. Um par de registos aponta para a parte privada, e um par aponta para a parte partilhada. Os Processos 1 e 2 têm o seu par de relocalização limite para o apontador do bloco partilhado para as mesmas localizações de memória física. A extensão de sistema operativo deve então proporcionar meios para o programa identificar um bloco como sendo partilhado e providenciar sistema de chamadas, desta forma causando os segmentos partilhados para serem ligados a uma localização de memória comum.
A interligações na rede é a componente de hardware chave da memória partilhada do multiprocessador. A interligação na rede é usada por qualquer CPU para qualquer acesso à memória. Experiências com estes CPUs mostram se a rede é implementada como um bus partilhado, o bus irá saturar uns quatro CPUs. Podem - se construir interligações na rede mais sofisticadas. Mas em toda a memória partilhada dos multiprocessadores se utilizam memórias cache especializadas para diminuir o carregamento nas interligações da rede e aumentar o desempenho de cada processo.
Afinação de desempenho
Caching numa partição de memória num processador
Memórias cache podem aumentar substancialmente o desempenho de um computador (até mesmo um uniprocessador) mantendo frequentemente informação usada na alta velocidade de cache. Isto permite que o processador para carregar informação da cache - uma memória muito mais rápida que a memória primária normal – sem ter de usar o bus. Num multiprocessador, todas as CPUs podem tentar usar o bus comum ao mesmo tempo. Assim, esta contenção para o bus efectivamente limita o número de processadores que podem ser configurados no multiprocessador.
Incorporar uma memória cache em cada processador provou ser bastante efectivo porque permite ás máquinas de memória partilhada providenciarem uma escala de desempenho quase linear com o número de processadores, aproximadamente 20 (dependendo da natureza dos programas que executam na máquina). Para memórias partilhadas de multiprocessadores escalar um número ainda maior de processadores, o caching pode ser combinado com uma interligação da rede mais complexa.
Usando caches na memória partilhada de multiprocessadores introduz um novo problema. Suponha que uma estrutura de dados, D, é partilhada pelos Processos 1 e 2 nos processadores X e Y, respectivamente. Quando o Processo 1 lê D, é copiado da memória na cache X's. Se o Processo 2 fosse também para ler D, seria copiado na cache Y's ,e teria como resultado três cópias de D que existem na hierarquia de memória: o original na memória, uma cópia na cache X's, e outra cópia na cache Y's. Suponha que o Processo 1 escreve em D a estrutura de dados. Os três cópias dizem - se agora serem incoerentes, desde que eles contenham valores diferentes.
Esta situação é um problema sério num sistema de memória partilhada, desde que signifique que os programas para dois processos são escritos como se eles partilhassem a memória, mas cada processo percebe valores diferentes na mesma cela de memória.
Há várias abordagens para aguentar o problema. O primeiro é simplesmente para não permitir que se partilhe informação (código ou dados) para serem escondidas. O resultado é penalizar o desempenho da contenção de interligações na rede. A segunda abordagem é a não garantia da consistência de memória para memórias partilhadas. Se não houver cache, diz – se que o modelo de memória tem semântica fortemente consistente. Se um sistema de memória cached é fortemente consistente, o implementação de memória partilhada tem a mesma semântica que teria se não tivesse cached. Uma memória de consistência fraca permite que cada uma das duas cópias tenham valores diferentes por pequenos períodos de tempo. Uma memória de consistência fraca, depois, deve incorporar um esquema por fazer a memória coerente "rapidamente" depois de qualquer das cópias ter sido mudada com uma operação de escrita. As aplicações num sistema de memória de consistência fraca devem ser escritas para ter conhecimento da semântica da memória, e com uma sincronização explícita, para que os programas se comportem correctamente. Desta forma um sistema de memória de consistência fraca deve garantir que a sincronização primitiva possa ser implementada de forma a que se comporte correctamente independente do tipo de memória.
O mecanismo para assegurar coerência em todas as caches e a memória pode ser difícil construir, desde que deva ser capaz de descobrir a escrita, para que qualquer memória partilhada copie o momento em que acontece, em qualquer processador. Esta habilidade sugere que a coerência deva ser implementada pelo ICN e/ou caching hardware em cada máquina. Quando uma localização de memória partilhada é escrita, o mecanismo de caching deve imediatamente informar outro mecanismo de caching e/ou centraliza - lo facilmente em todas as outras máquinas que tenham cópias dos conteúdos de memória. Todas as copias, excepto a mais recentemente cópia escrita, são então invalidadas até que possam ser actualizadas com o novo valor. Quando a memória partilhada se tornar incoerente, o mecanismo coerente pode actualizar a cópia e a memória original imediatamente, escrevendo os novos dados na memória quando escreve na cache. Esta abordagem é chamada a estratégia de escrever através. Alternativamente, o mecanismo pode actualizar a cache imediatamente mas adiar, num curto espaço de tempo, a actualização da memória. Esta estratégia é chamada a estratégia de escrever de volta.
11.5 - Resumo
Ao gestor de memória é exigido administrar a memória executável, atribuindo–a a processos diferentes com forme precisem. Providencia mecanismos que permitem à informação migrar para cima para abaixo na hierarquia de memória. Ligação de endereço é uma barreira fundamental para o movimento de dados. Isto é porque o ambiente de tradução de programa tradicional causa pontos no espaço de endereçamento de um programa para ser ligado a localizações de memória físicas antes do programa começar a executar. A ligação estática inibe a habilidade do gestor para mover um espaço de endereçamento em redor da memória.
O mecanismo subjacente por adiar ligações do tempo de carga ao runtime é o registo de relocalização de hardware. Este mecanismo permite ao gestor de memória mover facilmente o espaço de endereçamento ao redor porque os endereços são ligados como um compensatório dos conteúdos do registo de relocalização em cada referência de memória. Os registo limite complementa o registo de relocalização e, a um custo pequeno em complexidade, permite ao hardware providenciar um mecanismo de isolamento robusto. Com registos de relocalização e de limite, o processo pode referenciar só a parte da memória primária que o atribuiu.
Estratégias de troca permitem que a memória seja partilhada entre processos mais activos depois possam ser carregados na memória de vez. A memória virtual estende a tecnologia de troca carregando só partes do espaço de endereçamento de um processo imediatamente. Gestores de memória contemporâneos evoluíram (ou estão a evoluir) para projectos de memória virtuais.
Armado com conhecimentos de gestão de memória provenientes deste capítulo, você está agora pronto para saltar para o próximo capítulo, que discute sistemas de memória virtuais em mais detalhe.
Tradução realizada por:
Ana Leal Nº2195
Joaquim Prudêncio Nº3503