
Encaminhamento em redes IPV 6
Paulo Alexandre Cáceres Ferreira
Luís Filipe Roberto Farinha
Departamento de Engenharia Informática
Escola Superior de Tecnologia de Tomar
21 de Julho de 2003
Queremos desde já frisar que os agradecimentos não têm ordem definida, ou seja, não existe mais gratidão ou menos gratidão pela ordem que vai ficar definida.
Ao Engenheiro Luís Oliveira e Engenheiro Carlos Queiroz, pela orientação e apoio no decorrer deste projecto, desde os seus primórdios até à sua conclusão. Pela disponibilidade prestada sempre que necessária, reforçando um apoio que teve sempre presente em todas as situações, mesmo nas mais complicadas.
Ao Engenheiro José Ramos e Engenheiro José Pereira, pelo apoio e incentivo prestado durante este semestre, e pela ajuda disponibilizada sempre que possível.
Ao Engenheiro Carlos Friaças, Engenheiro de Sistemas da FCCN, no apoio prático e científico que nos disponibilizou ao longo da elaboração deste projecto. A sua colaboração contribuiu em muito para a resolução de problemas, resultantes de cenários idealizados por nós, que só se realizaram graças à disponibilidade e força de vontade deste homem.
Aos alunos do terceiro ano de Engenharia Informática da Escola Superior de Tecnologias de Tomar do Politécnico de Tomar, pela compreensão e paciência, perante as nossas experiências, e pela ajuda disponibilizada quando necessária.
Às nossas namoradas por nos apoiarem nos momentos mais difíceis, quando quase em desespero pensávamos em desistir, estiveram sempre presentes, apoiando e incentivando a seguir em frente e a tornar este momento possível. Um beijo especial à
Susana Filipa Sequeira Rodrigues, e Tânia Isabel Luciano Antunes.
Para todas as pessoas que também nos ajudaram mas que aqui não estão mencionadas, não sendo menos imprescindíveis neste trabalho, merecem um grande obrigado por nos ajudarem a dar um passo importante nas nossas vidas.
Neste projecto vamos testar três protocolos de encaminhamento, em vários cenários IPv6 de modo a verificar as suas limitações e quais as suas potencialidades. Vamos explicar o funcionamento tanto do OSPFv3, como do RIPng e do IS-IS, as principais diferenças entre os protocolos da família Link Sate OSPFv3 e IS-IS e exemplificar todos estes protocolos em ambientes diversos onde foram encontradas algumas das suas limitações.
Também vamos exemplificar os procedimentos a tomar em conta para a implementação de qualquer um destes protocolos, de forma a que se insiram sem problemas em cenários reais.
Vamos exprimir as nossas conclusões e opiniões baseadas nos testes executados ao longo deste projecto de forma a facilitar a escolha de protocolos para os vários tipos de cenários que podem ser desenvolvidos.
1.1 IPv4 – “O Irmão mais velho”
1.2.1 Espaço de endereçamento alargado
1.2.2 Mecanismos de segurança incluídos
1.2.3 Melhor desempenho para aplicações
do tipo multimédia
1.2.4 Cabeçalho modificado e
simplificado
1.4 Divisão do espaço de endereçamento
1.6 Auto-configuração Stateless
1.6.1 Criação de um endereço link-local
1.6.2 Criação dos endereços globais e site-local
1.7 Auto-configuração Stateful
2.1.1 Início a “frio” do protocolo RIP
2.1.2 Funcionamento do RIP com
interrupção de uma ligação
2.2.1 A base de dados link state
2.2.4 Segurança nas actualizações
2.3.1 Bases do protocolo IS-IS
2.3.3 Particularidades do IS-IS
3.3 Configuração do Zebra IPV4
3.4 Configuração do Zebra IPV6
3.5 Ligação à FCCN utilizando RIPng
3.8 Ligação à FCCN utilizando OSPFv3
Ligação
à FCCN utilizando RIPng
Ligação
à FCCN utilizando OSPFv3
Figura
2: Divisão do espaço de endereçamento.
Figura
4: Rede para ilustração do RIP
Figura
5: Rede com quebra de uma ligação
Figura
6: Rede para ilustração do RIP
Figura
7: Rede com quebra de duas ligações
Figura
8: Rede usada para ilustrar o OSPF
Figura
11: Túnel para resolução de fracturas em áreas
Figura
12: Exemplo de parte de um pacote do IS-IS
Figura
13: Rede usada em testes ipv4
Figura
14: Pacote RIP versão 1
Figura
15: Pacote RIP versão 2
Figura
16: Rede para implementação IPv6
Figura
17: Router Advertisement
Figura 18: Pacote RIP next generetion
Figura
19: Rede de ligação à FCCN utilizando RIPng
Figura
24: Rede de ligação à FCCN utilizando OSPFv3
Figura
25: Pacote OSPFv3 Hello
Figura
26: Pacote OSPFv3 LS Update
Figura
27: Pacote OSPFv3 LS Acknowledge
A Internet como a conhecemos, não é mais do que um conjunto de redes interligadas, de modo a estabelecer comunicação global entre várias entidades ou pessoas. Para que essa comunicação seja possível, na interligação das redes existem dispositivos designados por routers que encaminham pacotes provenientes de uma rede para outra. Os routers para encaminharem os pacotes, utilizam protocolos de encaminhamento. Esses protocolos podem ser de dois tipos IGP (Internal Gateway Protocol ou EGP (External Gateway Protocol), onde uns são orientados para o encaminhamento interno (IGP) e outros para o externo (EGP).
Vamos relatar o funcionamento de três protocolos de IGP, e criar cenários propícios ao teste dos protocolos de encaminhamento nas suas versões para IPv6. O RIPng, o IS-IS e o OSPFv3, são os protocolos escolhidos para análise de funcionamento em IPv6, pois estes protocolos são iguais aos seus antecessores de IPv4 no que diz respeito ao funcionamento, mas têm estruturas diferentes. Como foi necessário redesenhar estes protocolos de encaminhamento devido à mudança no protocolo IP, vamos desvendar que funcionalidades estão disponíveis em cada um, em cenários IPv6.
O que nos motivou a desenvolver este projecto, foi o facto de existir uma novidade no mundo das novas tecnologias que está em franco desenvolvimento. Essa tecnologia é designada de Ipv6, e tem vindo a fazer frente ao actual IPv4.
Capítulo 1
A Internet é um dos maiores símbolos da evolução nos finais do século XX. Presentemente é um meio de trabalho, de diversão, de convívio, de publicidade, entre outras coisas. Registou o seu maior crescimento de utilizadores na última década, e é sem duvida um dos assuntos mais mediáticos da nossa era. Proporciona conflitos políticos, gera lucros ou prejuízos nas empresas, proporciona novas oportunidades, assim como elimina algumas antigas, mas é sem duvida o comum dos utilizadores que retira mais benefícios da Internet. Cada vez mais dispomos de tudo na Internet, desde a informação necessária para a pesquisa que estamos a fazer para o nosso emprego, aquele livro que nunca encontramos à venda na livraria, ou a banda sonora daquele filme que toda a gente detesta mas nós adoramos. Estas facilidades provocaram um crescimento do número de utilizadores, o que por sua vez provoca problemas no funcionamento da rede. O problema mais visível provocado pelo crescimento da Internet está relacionado com a escassez dos endereços IPv4 disponíveis e com a forma como estes foram atribuídos.
1.1 IPv4 – “O Irmão mais velho”
Criado à cerca de 3 décadas, este protocolo ainda hoje é usado. Surgiu numa altura em que a Internet era constituída por um número muito limitado de computadores que usavam aplicações com necessidades bastante diferentes das que são usadas actualmente. O IPv4 é robusto, fácil de implementar e de usar, e provou ser eficiente até os dias de hoje.
De facto foi a expansão tão repentina da Internet, e o consequente esgotamento de espaço de endereçamento, que levantou os maiores problemas ao IPv4. Apesar de estar bem constituído, padece de vários problemas: segurança (Spoofing), espaço de endereçamento insuficiente para as actuais necessidades (teoricamente existem 32bits = 4294967296 de endereços totais disponíveis), etc. Na tentativa de atenuar o problema da escassez de endereços, foi concebido o NAT (Network Address Translator), que permite a tradução de endereços privados (192.168.xxx.xxx) em públicos, possibilitando assim a comunicação de um “grupo” de máquinas com a Internet utilizando um único endereço público. Também o NAT nos levanta alguns problemas, por exemplo impede o uso de alguns serviços.
1.2 Inovações
Sendo uma evolução do protocolo IPv4, o IPv6 demonstra que se pode aprender com os erros. Possui uma série de reparos, em relação à versão anterior, mas também é impulsionado pelas novas funcionalidades.
- Espaço de endereçamento alargado (128 bits para o endereçamento);
- Maior facilidade de configuração (semelhante a plug-and-play: stateless address configuration);
- Melhor desempenho na mobilidade;
- Mecanismos de segurança incluídos, proporcionado maior privacidade e confidencialidade dos dados;
- Melhor desempenho para aplicações do tipo multimédia;
- Cabeçalho modificado, e simplificado;
- Dado a simplificação do cabeçalho, este permite o aumento do desempenho dos nós intermédios.
1.2.1 Espaço de endereçamento alargado
Durante a criação do IPv4, pensou-se que 32bits era mais que suficiente. As actuais situações provam exactamente o contrário. Para a resolução desse problema, o IPv6 contém 128 bits de endereçamento, o que significa um espaço de endereçamento muito superior ao do se antecessor IPv4. Este novo espaço de endereçamento permite a atribuição de um milhão de endereços por micro-segundo durante aproximadamente 1019 anos.
1.2.2 Mecanismos de segurança incluídos
O IPv6 utiliza o IPSec (Internet Protocol Security) intrinsecamente nos seus pacotes, fazendo assim com que a segurança seja normalizada logo de base, facilitando desta maneira a comunicação e interacção entre diferentes implementações de IPv6.
1.2.3 Melhor desempenho para aplicações do tipo multimédia
Devido introdução de novos campos no cabeçalho IPv6, permite que os routers possam distinguir mais facilmente os diferentes fluxos de tráfego e encaminhar pacotes que tenham o mesmo par origem destino, fazendo com que sofram um tratamento especial de acordo com as suas necessidades.
1.2.4 Cabeçalho modificado e simplificado
O número de campos do cabeçalho IPv6 foi reduzido em relação ao seu antecessor. Algumas das opções foram colocadas em cabeçalhos de extensão de acordo com a os nós onde são processadas. As opções disponíveis de cabeçalhos de extensão são:
- Opções
nó-a-nó (Hop-by-Hop Options);
- Encaminhamento (Routing Header);
- Fragmentação (Fragment);
- Opções de Destino (Destination Options);
- Autenticação (Authentication);
- Privacidade
(Encapsulation Security Payload).
Os cabeçalhos de extensão são indicados pelo campo Next Header, que existe no cabeçalho base do IPv6, e pode voltar a surgir nos cabeçalhos de extensão se existir mais algum para além do actual.
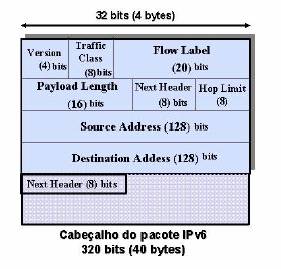
Figura 1: Cabeçalho IPv6
O protocolo IP é responsável por uma das mais importantes funções da estrutura protocolar, funcionando na camada de rede, sendo responsável por fazer a comunicação entre redes de computadores.
Os endereços IPv6 podem ser classificados num de três tipos, consoante o conjunto de máquinas que permitem endereçar:
Unicast – Identifica uma única
interface. Os endereços unicast podem
subdividir-se em link-local}; site-local e global:
link-local - Os endereços Ipv6 deste tipo são caracterizados pelo prefixo fe80::/16. Ao prefixo fe80 é adicionado um identificador único de 64 bits que é calculado à custa do endereço MAC da interface através do algoritmo EUI-64 (ver: 1.5). Este tipo de endereços são utilizados nas seguintes situações:
· Na ausência de routers que forneçam o prefixo de rede;
· Quando se pretende comunicar com máquinas que estejam na mesma rede. Estes endereços são semelhantes aos endereços IPv4 usados nas redes privadas;
· Na auto-configuração de endereço (stateless, ver: 1.6).
site-local - Usado quando uma organização que não pretende ter ligação à Internet, mas pretende que os diversos nós que constituem a sua rede possam comunicar sem qualquer impedimento. Este tipo de endereços são caracterizados pelo prefixo fec0::/16.
global - Os endereços globais, são endereços unicast que são “visíveis” no exterior, ou seja, é o endereço que se utiliza para comunicar entre redes distintas na Internet.
Anycast – Identifica um conjunto de interfaces (tipicamente pertencentes a diferentes nós da rede). Um pacote com um endereço de destino anycast é entregue ao interface, que de acordo com o protocolo de encaminhamento, lhe está mais próximo;
Multicast – Identifica um conjunto de interfaces. Um pacote com um endereço de destino multicast é enviado para todos os interfaces identificados por esse endereço multicast.
1.4 Divisão do espaço de endereçamento
O espaço de endereçamento está dividido da seguinte forma:
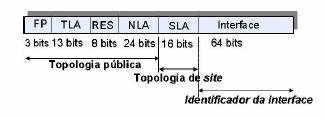
Figura 2: Divisão do espaço de endereçamento
- FP (Format Prefix) - Prefixo de três bits que identifica o tipo de endereço (unicast
global, unicast local);
- TLA (Top-Level Aggregation) - Nível mais alto da hierarquia de routing;
- RES (Reserved) - Este campo é reservado para uso futuro. Pode ser usado para expandir os campos que lhe são adjacentes;
- NLA (\emph{Next-Level Aggregation Identifier}) - Indica o nível seguinte de agregação. É usado por organizações associadas a um TLA, para formar uma estrutura hierarquia de endereçamento;
- SLA (Site-Level Aggregation Identifier) - É atribuído a organizações individuais para definirem as suas sub-redes. Pode ser usado para definir uma hierarquia de endereçamento, do qual resultam tabelas de encaminhamento menores;
- Interface – É construído através do algoritmo EUI-64 (ver: 1.5).
1.5 IEEE EUI-64
A norma IEEE
EUI-64 usa o endereço MAC de uma interface, transformando os seus 48 bits nos 64 bits necessários para o sufixo da rede IPv6, obtendo assim um
endereço que supostamente é único (devido à unicidade dos MAC Address). Basicamente consiste em dividir o endereço MAC ao
meio, ficando com a parte que identifica o fabricante de um lado, e o número de
série de outro. Após isto introduz-se entre estes dois campos dois octetos
(0xFF e 0xFE), obtendo assim os 64 bits que compõem o sufixo.
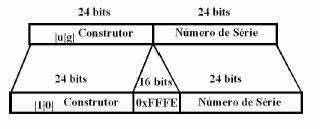
Figura 3: EUI-64
Quando num endereço o campo u (ver na figura 3) é igual a 1, indica que o endereço é global, quando o u é igual a 0, indica que estamos perante um endereço local. No que diz respeito ao campo g, quando é igual a 0, o endereço é individual, quando igual a 1 é de grupo.
1.6
Auto-configuração Stateless
Este processo não requer qualquer tipo de configuração manual dos host, uma configuração mínima nos routers e a inexistência de servidores adicionais. A auto-configuração permite a um host obter um endereço de um modo completamente transparente para o utilizador, unicamente utilizando as informações locais disponíveis e a informação enviada pelos routers. Os routers enviam os prefixos que identificam as sub-redes, enquanto os hosts geram um identificador para a interface que vai identificar unicamente a interface nessa sub-rede. Um endereço resulta da combinação dos dois.
1.6.1
Criação de um endereço link-local
A interface gera o link-local assim que for activada. Este é o único endereço que um host é capaz de criara na ausência de um router, mas é suficiente para a comunicação com os vários nós da mesma rede.
1.6.2
Criação dos endereços globais e site-local
Para a criação deste tipo de endereços, é usado um processo de Neighbor Discovery, onde é executado um conjunto de procedimentos (ver 1.6.3).
1.6.3
Neighbor Discovery
Este processo descreve como os nós IPv6 obtêm informações sobre o ambiente em que se encontram. Este processo combina e melhora o ARP (Address Resolution Protocol) e o ICMP (Control Message Protocol) já disponíveis em IPv4. Ao dar início à comunicação com a rede, a máquina solicita aos routers (Neighbor Discovery) que lhe enviem um pacote (Router Advertisement) que irá ser usado para a construção do endereço global. O router que vai servir a rede onde essa máquina se encontra responde enviando um Router Advertisement, mesmo que este tenha de ser enviado fora do intervalo definido. A informação que vem nesse pacote é o prefixo da rede (64 bits), que juntamente com a parte construída pela norma EUI-64 completa o endereço usado para a comunicação com o exterior. Entretanto é executado o DAD (Duplicated Address Discover), para verificar se existe alguém com um endereço igual ao criado (Link-Local e global). O Neighbor Discovery utiliza o protocolo ICMPv6 (Control Message Protocol version 6) para a troca de mensagens, que podem ser de cinco tipos diferentes:
· Router Solicitation (RS) – Para que sejam enviados Router Advertisement;
· Router Advertisement (RA) – Avisos que informam da presença do router que os envia;
· Neighbor Solicitation (NS) – Para determinar os endereços dos nós vizinhos;
·
Neighbor Advertisement (NA) - Resposta ao Neighbor
Solicitation;
· Redirect – Utilizado pelo router para indicar o melhor caminho.
1.7
Auto-configuração Stateful
Na Auto-configuração stateful os hosts obtêm os endereços para as interfaces, a informação de configuração e os parâmetros através de um servidor a executar o protocolo DHCPv6 (Dynamic Host Configuration Protocol version 6). O servidor mantém uma base de dados que contém a pista de qual o endereço que foi atribuído a certo host. O DHCPv6 é muito semelhante ao DHCP utilizado em IPv4.
Este tipo de
configuração existe porque apesar de todas as auto-configurações que o IPv6
possui, não lhe é possível a distribuição dos endereços dos servidores DNS. A
auto-configuração stateful
permite-nos controlar os acessos à rede (através de MAC Address, número de hosts
limitado, etc.).
Capítulo 2
Protocolos da família do RIP são muitas vezes designados como protocolos Bellman-Ford, pois são baseados no algoritmo de cálculo do caminho com menor custo, descrito por R.E.Bellman. Esta família de protocolos tem vindo a ser usada em várias redes de comutação de pacotes, como por exemplo na Arpanet e na Cyclades.
O RIP devido à sua forma de funcionamento destina-se a pequenos conjuntos de redes normalmente sob administração da mesma organização.
2.1.1 Início a “frio” do protocolo RIP
Para explicar o funcionamento do RIP, vamos considerar uma rede com cinco nós e seis ligações, não diferenciando entre hosts e routers, sub-redes e ligações, switches e terminais, para que se torne simples. Os nós dessa rede, são capazes de trocar pacotes, e o propósito das trocas de encaminhamento, é a computação das tabelas de encaminhamento, que permitem aos nós saberem como ”chegar” aos outros nós. Cada um dos nós é representado como A, B, C, D e E (ver figura 4). As tabelas de encaminhamento vão ter uma entrada por cada um dos endereços anteriormente referidos.
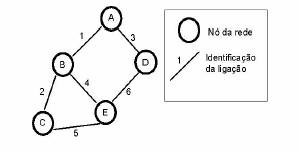
Figura 4: Rede para ilustração do RIP
Inicialmente vamos admitir que as ligações têm custo unitário afim de simplificar a explicação do funcionamento simples do RIP.
Supondo agora que se inicializa a rede ligando todos os nós simultaneamente, esta situação é designada por cold start. Cada nó só conhece as redes às quais está directamente ligado. Nesta fase não têm conhecimento de quantos nós existem. Por este motivo aquando o arranque da rede, as tabelas de encaminhamento de cada um dos nós só contêm as entradas referentes às redes às quais se encontra directamente ligado, como podemos verificar na tabela seguinte:
|
De A para |
Ligação |
Custo |
|
A |
local |
0 |
O nó A vai transmitir através de broadcast para todos os seus vizinhos, ou seja, para o nó B e D. B e D ao receber a mensagem de A, vão ser capazes de aumentar os seus conhecimentos a nível de topologia da rede, uma vez que ficam a conhecer a existência do nó A e a que redes está directamente ligado. Como exemplo, vamos verificar o que vai acontecer ao nó B após esta troca de informações. Antes do arranque da rede a tabela do nó B tinha a informação seguinte:
|
De B para |
Ligação |
Custo |
|
B |
local |
0 |
Após a rede iniciar, o nó B recebe pela ligação 1 o vector de distância A=0. Aquando a recepção da mensagem ele actualiza todas as distâncias adicionando o custo da ligação local. Após a adição, ele vai comparar a informação modificada com a sua tabela de encaminhamento, como observa que A ainda é desconhecido perante a sua tabela, ele adiciona esse registo, ficando a tabela de encaminhamento com o seguinte aspecto:
|
De B para |
Ligação |
Custo |
|
B |
local |
0 |
|
A |
1 |
1 |
Após a alteração da tabela de encaminhamento envia-a para as ligações a que está directamente ligado (1, 4, 2). Durante este período de tempo, o nó D já recebeu a mensagem de A e já actualizou a sua tabela de encaminhamento (como podemos verificar na tabela seguinte), e já transmitiu o seu vector de distância nas ligações 3 e 6 (com a informação D=0, A=1).
|
De D para |
Ligação |
Custo |
|
D |
local |
0 |
|
A |
3 |
1 |
A mensagem enviada por B vai ser recebida por A, C e E; a de D vai ser recebida por A e E. Vamos supor que a mensagem de B é recebida primeiro. O nó A ao receber a mensagem de B vai actualizar as distâncias para B=1 e A=2, como A=2 é maior que a distância que A contém na sua tabela, só o registo de B vai ser actualizado, pois este ainda não existe na tabela. Após receber a mensagem de B, recebe também a mensagem de D, ficando a tabela de encaminhamento com o seguinte aspecto:
|
De A para |
Ligação |
Custo |
|
A |
local |
0 |
|
B |
1 |
1 |
|
D |
3 |
1 |
O nó C vai receber pela ligação 2 o vector distância B=0, A=1 e actualiza a sua tabela:
|
De C para |
Ligação |
Custo |
|
C |
local |
0 |
|
B |
2 |
1 |
|
A |
2 |
2 |
Pela ligação 4 o nó E também recebe um vector distância com a informação B=0 e A=1:
|
De E para |
Ligação |
Custo |
|
E |
local |
0 |
|
B |
4 |
1 |
|
A |
4 |
2 |
Após a actualização da tabela de encaminhamento por parte do nó E, este vai receber outro vector distância pela ligação 6 com a informação D=0 e A=1, actualiza-o para D=1 e A=2, e vai deparar-se com uma igualdade no que diz respeito ao caminho para o nó A, pois na sua tabela de encaminhamento, já contém um registo de A com o mesmo custo (2), só que com ligações diferentes, ou seja, existem caminhos para o nó A com o mesmo custo mas um pela ligação 4 e outro pela 6. Perante esta situação, dado que os custos são iguais, ele vai manter o caminho através da ligação 4 (só o mantém porque continua a recebe-lo continuamente, se não substituía-o). Sendo assim só irá actualizar na tabela de encaminhamento o registo D=1, ficando a tabela de encaminhamento do nó E com o formato apresentado na tabela seguinte:
|
De E para |
Ligação |
Custo |
|
E |
local |
0 |
|
B |
4 |
1 |
|
A |
4 |
2 |
|
D |
6 |
1 |
Os nós A, C e E após actualizarem as suas novas tabelas de encaminhamento, os vectores distância vão ter as seguintes formas:
- De A: A=0, B=1, D=1 nas ligações 1 e 3
- De C: C=0, B=1, A=2 nas ligações 2 e 5
- De E: E=0, B=1, A=2, D=1 nas ligações 4, 5 e 6
Estas mensagens vão desencadear uma actualização nas tabelas de B, D e E:
|
De B para |
Ligação |
Custo |
|
B |
local |
0 |
|
A |
1 |
1 |
|
D |
1 |
2 |
|
C |
2 |
1 |
|
E |
4 |
1 |
|
De D para |
Ligação |
Custo |
|
D |
local |
0 |
|
A |
3 |
1 |
|
B |
3 |
2 |
|
E |
6 |
1 |
|
De E para |
Ligação |
Custo |
|
E |
local |
0 |
|
B |
4 |
1 |
|
A |
4 |
2 |
|
D |
6 |
1 |
|
C |
5 |
1 |
A partir deste instante os nós B, D e E podem usar os seguintes vectores de distância:
- De B: B=0, A=1, D=2, C=1, E=1 nas ligações 1, 2 e 4
- De D: D=0, A=1, B=2, E=1 nas ligações 3 e 6
- De E: E=0, B=1, A=2, D=1, C=1 nas ligações 4, 5 e 6
Estas mensagens vão ser recebidas pelos nós A,C e D, e as respectivas tabelas vão tomar as seguintes formas:
|
De A para |
Ligação |
Custo |
|
A |
local |
0 |
|
B |
1 |
1 |
|
D |
3 |
1 |
|
C |
1 |
2 |
|
E |
1 |
2 |
|
De C para |
Ligação |
Custo |
|
C |
local |
0 |
|
B |
2 |
1 |
|
A |
2 |
2 |
|
E |
5 |
1 |
|
D |
5 |
2 |
|
De D para |
Ligação |
Custo |
|
D |
local |
0 |
|
A |
3 |
1 |
|
B |
3 |
2 |
|
E |
6 |
1 |
|
C |
6 |
2 |
Nesta fase, o algoritmo convergiu. A, C e D vão preparar os seus novos vectores distância e enviá-los para as suas ligações locais. Enquanto não existir alterações na rede, não irão fazer mudanças nas tabelas de encaminhamento dos nós, pois as rotas estão estabelecidas. Atingindo esta etapa já nos é permitido dizer que cada um dos nós da rede, conhece a totalidade da topologia da rede.
2.1.2 Funcionamento do RIP com interrupção de uma ligação
Na secção anterior deparámo-nos com um cenário sem problemas. Agora vamos analisar o que acontece, quando nem tudo corre bem.
Para simular um cenário com problemas, vamos considerar que na ligação 1, onde os pacotes circulam sem qualquer problema, de repente, sem qualquer explicação a ligação “cai” (situação que ocorre frequentemente em redes reais) como podemos verificar na figura 5.
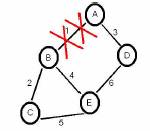
Figura 5: Rede com quebra de uma ligação
Assim que acontece a quebra na ligação os nós que lhe estão adjacentes (neste caso A e B), vão aperceber-se que a ligação não se encontra disponível, logo vão actualizar as suas tabelas de encaminhamento com um custo infinito (inf[1]) (na prática o custo é 16, pois o RIP só permite 15 saltos). As tabelas de encaminhamento do nó A e do nó B, vão conter o custo inf para todos os nós em que a ligação era efectuada pelo caminho 1, logo as tabelas de encaminhamento desses dois nós vão tomar o aspecto demonstrado nas tabelas seguintes:
|
De A para |
Ligação |
Custo |
|
A |
local |
0 |
|
B |
1 |
inf |
|
D |
3 |
1 |
|
C |
1 |
inf |
|
E |
1 |
inf |
|
De B para |
Ligação |
Custo |
|
B |
local |
0 |
|
A |
1 |
inf |
|
D |
1 |
inf |
|
C |
2 |
1 |
|
E |
4 |
1 |
A mensagem enviada por A vai ser recebida por D que vai comparar a mensagem com os registos da sua tabela, este verifica que os registos da mensagem após terem sido actualizados por ele, ou são maiores ou iguais aos que ele mantém na sua tabela, excepto a ligação 3 por onde ele recebeu a mensagem, é exactamente o utilizado para chegar ao nó B, isto é, o D para chegar ao B utilizava o nó A, mas este agora diz-lhe que não consegue chegar a B, logo D tem de actualizar o novo valor na sua tabela dizendo que por a ligação 3 também já não consegue chegar a B. Com estas modificações, a tabela de encaminhamento de D vai tomar o seguinte aspecto:
|
De D para |
Ligação |
Custo |
|
D |
local |
0 |
|
A |
3 |
1 |
|
B |
3 |
inf |
|
E |
6 |
1 |
|
C |
6 |
2 |
Assim da mesma maneira, C e E vão também actualizar as suas tabelas de encaminhamento da mesma forma que o nó D o fez, logo as mensagens enviadas após as actualizações são:
- De D: D=0, A=1, B=inf, E=1, C=2, nas ligações 3 e 6
- De C: C=0, B=1, A=inf, E=1, D=2, nas ligações 2 e 5
- De E: E=0, B=1, A=inf, D=1, C=1, nas ligações 4, 5 e 6
Estas mensagens vão “disparar” uma actualização nas tabelas de encaminhamento dos nós A, B, D e E para os seguintes aspectos representados nas tabelas seguintes:
|
De A para |
Ligação |
Custo |
|
A |
local |
0 |
|
B |
1 |
inf |
|
D |
3 |
1 |
|
C |
3 |
3 |
|
E |
3 |
2 |
|
De B para |
Ligação |
Custo |
|
B |
local |
0 |
|
A |
1 |
inf |
|
D |
4 |
2 |
|
C |
2 |
1 |
|
E |
4 |
1 |
|
De D para |
Ligação |
Custo |
|
D |
local |
0 |
|
A |
3 |
1 |
|
B |
6 |
2 |
|
E |
6 |
1 |
|
C |
6 |
2 |
|
De E para |
Ligação |
Custo |
|
E |
local |
0 |
|
B |
4 |
1 |
|
A |
6 |
2 |
|
D |
6 |
1 |
|
C |
5 |
1 |
A partir deste instante os nós A, B, D e E podem preparar os seus vectores de distância:
- De A: A=0, B=inf, D=1, C=3, E=2 na ligação 3
- De B: B=0, A=inf, D=2, C=1, E=1 nas ligações 2 e 4
- De D: D=0, A=1, B=2, E=1, C=2 nas ligações 3 e 6
- De E: E=0, B=1, A=2, D=1, C=1 nas ligações 4, 5 e 6
Estas mensagens vão ser recebidas pelos nós A, B e C, e as respectivas tabelas vão tomar as seguintes formas:
|
De A para |
Ligação |
Custo |
|
A |
local |
0 |
|
B |
3 |
3 |
|
D |
3 |
1 |
|
C |
3 |
3 |
|
E |
3 |
2 |
|
De B para |
Ligação |
Custo |
|
B |
local |
0 |
|
A |
4 |
3 |
|
D |
4 |
2 |
|
C |
2 |
1 |
|
E |
4 |
1 |
|
De C para |
Ligação |
Custo |
|
C |
local |
0 |
|
B |
2 |
1 |
|
A |
5 |
3 |
|
E |
5 |
1 |
|
D |
5 |
2 |
Novamente os nós A, B e C vão novamente preparar e enviar os seus novos vectores distância, mas volta tudo a um tipo de ponto de “repouso”, pois apesar de continuarem a enviar mensagens, não haverá actualizações nas tabelas de encaminhamento, e a topologia da rede é de novo conhecida por todos os nós.
2.1.3 Formação de ciclos
Vamos de seguida simular uma situação em que ocorrem loops (ciclos) na rede, para isso, temos que admitir, que ao contrário do que admitimos anteriormente de que o custo de todas as ligações é de uma unidade, agora vamos dizer que a ligação 5 que liga o nó E ao nó C (por ligação local) irá ter um custo de 10 unidades.
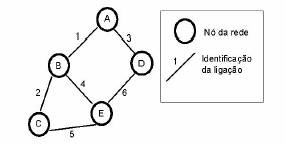
Figura 6: Rede para ilustração do RIP
Sendo assim é óbvio que a diferença mais marcante nas tabelas de encaminhamento (já estabilizadas), será o caminho que o nó E vai considerar para chegar a C. Podemos verificar na tabela seguinte o aspecto das tabelas de encaminhamento dos respectivos nós da rede, que querem chegar ao nó C:
|
De |
Ligação |
Custo |
|
A para C |
1 |
2 |
|
B para C |
2 |
1 |
|
C para C |
local |
0 |
|
D para C |
3 |
3 |
|
E para C |
4 |
2 |
Como verificámos o nó E vai evitar a ligação número 5 para chagar a C, dado que mesmo seguindo pela ligação 4 e depois a ligação 2, o custo é inferior do que utilizando a ligação 5.
Com estas condições iniciais, agora vamos supor que a ligação número dois é quebrada. Após a interrupção desta ligação, como já foi referenciado anteriormente, o nó B (e o C também, mas como estamos a analisar somente as rotas dos nós A, B, D, E para C, vamos esquecer um pouco a acção de C na rede) vai anunciar que para C pela ligação 2 passa a ter custo inf.
Imaginemos agora que quando B vai enviar a sua tabela de encaminhamento, ele recebe a tabela de A a informar que A consegue chegar a C através da ligação 1, como B para chegar a C tem custo infinito vai actualizar a sua tabela para o seguinte aspecto:
|
De |
Ligação |
Custo |
|
B para C |
1 |
3 |
Como A para chegar a C também usa a ligação 1, o que vai acontecer é que quando A quiser comunicar com C envia o pacote para B, para este enviar para C, mas B na sua tabela diz que para chegar a C tem de enviar pela ligação 1, e envia de novo o mesmo pacote a A, e assim sucessivamente criando um ciclo. Esse mesmo ciclo, só termina, quando após várias trocas de tabelas (como cada vez que recebem um vector distância aumentam em uma unidade o custo antes de ir comparar à tabela os valores) o caminho de E para C pela ligação 4, irá ter um custo superior ao custo que utilizaria para chegar a C através da ligação 5, ai a rede chegará novamente a um estado que se pode considerar estável (como podemos verificar na tabela seguinte).
|
De |
Ligação |
Custo |
|
A para C |
1 |
12 |
|
B para C |
4 |
11 |
|
C para C |
local |
0 |
|
D para C |
6 |
11 |
|
E para C |
5 |
10 |
2.1.4 Contagem para infinito
Continuando o raciocínio da secção 2.1.2, onde temos uma rede estabilizada, com uma ligação a menos (a ligação número 1 tinha falhado), vamos admitir que agora a ligação 6 também é quebrada (como podemos verificar na figura 7).
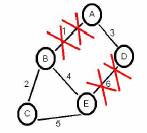
Figura 7: Rede com quebra de duas ligações
Após a quebra da ligação 6, o nó D actualizou a sua tabela de encaminhamento para:
|
De D para |
Ligação |
Custo |
|
A |
3 |
1 |
|
B |
6 |
inf |
|
C |
6 |
inf |
|
D |
local |
0 |
|
E |
6 |
inf |
Logo após actualizar a sua tabela o nó D, passa a enviar o seu vector, que é recebido por A, este ao actualizar a sua tabela, verificaria que todos os nós à excepção de D estavam inacessíveis. Neste caso o algoritmo teria convergido, mas se antes de isso acontecer, A enviar o seu vector (A=0, B=3, C=3, D=1, E=2), a tabela de D será actualizada para:
|
De D para |
Ligação |
Custo |
|
A |
3 |
1 |
|
B |
3 |
4 |
|
C |
3 |
4 |
|
D |
local |
0 |
|
E |
3 |
3 |
Novamente estamos perante um ciclo, mas como B, D e E estão isolados de A e D não será possível convergir para um estado estável. Em cada troca, as distâncias B, C e E vão ser incrementadas de duas unidades. A este processo designamos de contagem-para-infinito. Esta contagem pode apenas ser parada através de uma convenção que estabeleça o significado de infinito (uma distância muito elevada superior à máxima distância possível da rede).
Este tema torna-se uma das maiores desvantagens do RIP devido às características anteriormente descritas.
2.1.5 Separação de horizontes
A separação de horizontes (split horizon) nasceu com o fim de minorar o problema da contagem-para-infinito, pois apesar de não resolver todas as situações que geram contagem-para-infinito, pelo menos evita essa situação na grande maioria dos casos.
Esta técnica baseia-se na seguinte observação: se o nó A quer comunicar com o nó X mas tem de passar por B, ou seja através de B, não faz sentido se B quiser comunicar com o nó X utilizar o nó A. É necessário anunciar na ligação entre os nós A e B qual o custo para o nó X.
A separação de horizontes que faz com que o nó não anuncie o custo para um nó destino através da ligação em que os pacotes são encaminhados para esse nó, ou seja, A não anuncia a B o custo que tem para chegar a X, para que B não o use para chegar a X. Também existe a separação de horizontes com “inverso envenenado” (poisonous reverse), em vez de não anunciar, ele anuncia mas com custo infinito, ou seja, este método é muito mais eficaz, pois assim A diz a B para não o utilizar, pois ele não consegue chegar a X.
Como um nó a utilizar esta técnica pode enviar vectores distância distintos nas suas diferentes ligações locais, dai a sua designação separação de horizontes.
Relativamente ao à secção 2.1.4, se utilizasse-mos a separação de horizontes com inverso envenenado em vez do nó A difundir o vector (A=0, B=3, C=3, D=1, E=2), iria difundir (A=0, B=inf, C=inf, D=inf, E=inf). Neste caso a tabela de encaminhamento de D tomava a seguinte forma:
|
De D para |
Ligação |
Custo |
|
A |
3 |
1 |
|
B |
6 |
inf |
|
C |
6 |
inf |
|
D |
local |
0 |
|
E |
6 |
inf |
Neste caso particular não se iriam formar ciclos, evitando a contagem-para-infinito.
2.1.6
Triggered updates
Quando os routers estão a funcionar no seu estado normal, estes difundem os seus vectores distância periodicamente. Se um router deixar de receber os vectores de um dos seus vizinhos, ele pode admitir que esse vizinho ficou inacessível, enviando vectores distância com essa informação. Esse tipo de decisão por parte do router logo após ter expirado um período de difusão (intervalo de tempo entre o envio de dois vectores distância sucessivos), não seria correcto, pois poderia ter acontecido problemas na transmissão, para a resolução desse problema, o tempo de vida dos registos tem de ser superior ao intervalo periódico de envio dos vectores de distância. Por exemplo no protocolo RIP os vizinhos somente são declarados inacessíveis após um intervalo de tempo correspondente a 6 vezes o período de difusão.
Colocar um período de difusão elevado para resolver a questão, é uma má política, pois se as condições da rede forem alteradas imediatamente após a difusão de um vector distância, terá de se esperar um período de difusão para alertar os vizinhos do sucedido, o que poderia trazer graves problemas ao funcionamento da rede. A solução deste problema passa por utilizar uma técnica designada por triggered updates, que segundo a qual, logo que um router se aperceba de mudanças nas suas tabelas de encaminhamento, este difunde imediatamente o seu vector distância.
A utilização desta técnica ajuda na resolução de alguns ciclos, pois como verificámos em exemplos anteriores, a possibilidade de formação de ciclos e a contagem-para-infinito foram provocados por mensagens de nós que se limitaram a repetir o estado em que as suas tabelas se encontravam antes das alterações da rede. E se a rede entrar num estado de contagem-para.infinito, este torna-se muito mais rápido.
2.1.7 RIPng
O RIPng (RIP next generation), é a versão do protocolo RIP que suporta IPv6, este protocolo, tem um funcionamento muito similar ao RIPv2, pois somente contém as devidas modificações para suportar o novo protocolo IPv6.
Este protocolo do tipo distance vector}, usa o número de saltos como métrica[2]. O método de comunicação entre nós deste protocolo, faz-se através de dois tipos de pacotes, o pacote Request e o pacote Response. O Request pede informação sobre um ou mais destinos, e pode ser transmitido por um router que acaba de ser ligado, ou por um router em que a informação relativa a um determinado destino expirou. Os Response (updates, transportam os vectores distância) são enviados periodicamente ou em resposta a um Request.
Os updates são difundidos em cada trinta segundos (ou mais rapidamente no caso do uso da técnica de triggered updates), e se um percurso não for actualizado durante 180 segundos a distância é alterada para infinito. Para que a rede não seja inundada por causa do triggered updates, estes são espaçados de um intervalo de tempo aleatório entre 1 e 5 segundos.
A medida de convenção para parar a contagem-para-infinito, é impondo um limite ao número de saltos permitidos, esse número no caso do RIPng é de 15, pois o número 16 é considerado infinito.
Os algoritmos de cálculo de distâncias do tipo link state foram construídos com o intuito de substituir os algoritmos do tipo distance vector, pois estes protocolos em vez de distribuírem as distâncias para os respectivos destinos, todos os nós contém um “mapa” da rede. Estes mapas, podem ser usados para computar melhores rotas, do que seriam computadas pelos protocolos de vector distância. Estas rotas serão tão precisas como se a computação fosse central, mas na realidade a computação continua a ser distribuída.
O OSPF (Open Shortest Path First) sendo um protocolo de estado de ligação, podemos designa-lo juntamente com o RIP como um protocolo de interior. Pertencendo o OSPF à família dos protocolos do tipo link state, é sem dúvida um dos potenciais substitutos do RIP, pois apesar da facilidade de configuração do RIP, o OSPF tem vantagens muito significativas o que faz dele um protocolo superior ao RIP em cenários reais.
Todos os protocolos desta família (link state), incluindo o OSPF, são baseados no conceito de “mapa distribuído”, ou seja, todos os nós da rede contêm uma cópia do mapa da rede, que é actualizada regularmente. Para extrair a informação necessária desse mapa (descobrir o caminho mais curto), usa o algoritmo Dijkstra. Nesta secção vamos examinar como realmente este mapa é representado por uma base de dados, como as actualizações são “inundadas” na rede, porque é que as actualizações do mapa têm de ser seguras, como as redes se podem separar e depois voltarem a juntar-se.
2.2.1
A base de dados link
state
O princípio destes protocolos de encaminhamento é muito simples, em vez de tentarem computar os melhores caminhos numa maneira distribuída, todos os nós mantêm uma cópia completa do mapa da rede, e fazem uma completa computação dos melhores caminhos deste mapa local. Esse mapa da rede, é mantido numa base de dados, onde cada registo representa uma ligação na rede. Para vermos em mais detalhe como funciona vamos novamente tomar como referência a rede da figura 8.
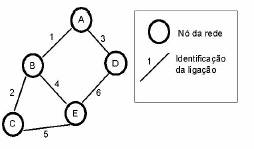
Figura 8: Rede usada para ilustrar o OSPF
A base de
dados correspondente à rede da figura 8, vai tomar a seguinte forma:
|
De |
Para |
Ligação |
Distância |
|
A |
B |
1 |
1 |
|
A |
D |
3 |
1 |
|
B |
A |
1 |
1 |
|
B |
C |
2 |
1 |
|
B |
E |
4 |
1 |
|
C |
B |
2 |
1 |
|
C |
E |
5 |
1 |
|
D |
A |
3 |
1 |
|
D |
E |
6 |
1 |
|
E |
B |
4 |
1 |
|
E |
C |
5 |
1 |
|
E |
D |
6 |
1 |
Cada nó contém um identificador de interface (no nosso caso estamos a usar o numero da ligação), e informação descrevendo o estado dessa ligação: o destino e a distância ou “métrica”. Com esta informação cada nó pode facilmente computar o caminho mais curto (shortest path) desde ele próprio para todos os outros nós. Como a tecnologia de hoje em dia cria processadores e máquinas cada vez mais potentes, essa computação, demora relativamente pouco tempo, tornando a computação de caminhos num problema menor. Como todos os nós vão ter bases de dados iguais, e executam os mesmos algoritmos sobre elas, as rotas vão ser coerentes. Em consequência os ciclos nunca ocorrem.
Como exemplo e seguindo a figura 8, se o nó A quiser comunicar com o nó C, irá haver computação por parte dos nós A e B, pois A, computou da base de dados que para chegar a C tem de passar por B, por isso envia o pacote pela ligação 1. B recebe o pacote de A e envia-o pela ligação 2 para que a comunicação seja realizada.
2.2.2
O protocolo flooding
O propósito de um protocolo de encaminhamento é adaptar as rotas às condições de mudança da rede. Isto só pode ser realizado se a base de dados for actualizada depois de cada mudança do estado da ligação.
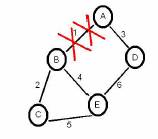
Figura 9: Mudanças na rede
Atendendo à figura 9, após a ligação 1 ter sido quebrada os nós A e B detectam essa mudança e vão actualizar os respectivos registos nas suas bases de dados, e vão transmiti-los aos restantes nós da rede. O protocolo usado para essa transmissão tem de ser tanto rápido, como fiável. Normalmente isto é atingido por um protocolo de flooding
(inundação). Logo após a detecção da falha da ligação 1, o nó A envia para D uma mensagem de actualização pela ligação 3:
De A, para B, ligação 1,
distância = infinito
O nó D após recebida a mensagem actualiza a sua base de dados e envia imediatamente a mesma mensagem para o nó E pela ligação 6, este (E) por sua vez, faz o mesmo que D mas agora envia a mensagem para os nós B e C pelas respectivas ligações.
Na realidade as mensagens são mais complicadas do que foi referido até aqui, pois se não existisse as devidas precauções, era bem possível que uma mensagem de actualização antiga votasse a passar pelo mesmo ponto poluindo a base de dados. Para que isso não aconteça, todas as mensagens contêm tanto um número de mensagem como um campo de tempo (tempo de vida), para que os nós possam distinguir as mensagens novas das mensagens antigas. Com estas protecções o protocolo de flooding trabalha da seguinte maneira:
- Recebe a mensagem, e procura pelo registo na sua base de dados.
- Se o registo ainda não estiver presente, adiciona-o à base de dados e “espalha” a mensagem.
- Se o número da base de dados é menor que o número da mensagem, substitui o registo pelo novo valor e difunde essa mensagem.
- Se o número na base de dados é maior, transmite o registo da base de dados numa nova mensagem através do interface de onde chegou a mensagem.
- Se os números são iguais não faz nada.
Neste tipo de protocolos, a operação broadcast causa a transmissão da mensagem em todas as interfaces, menos na interface em que se recebe a mensagem. Se nós assumirmos que o número inicial associado ao registo da base de dados é de uma unidade, a mensagem enviada por A seria:
De A, para B, ligação 1,
distância=infinito, número=2
Assim D vai actualizar a informação da sua base de dados e de seguida enviar (broadcast) a mensagem para o nó E. E faz exactamente o mesmo que D e transmite a mensagem para B e C, que também vão actualizar as suas bases de dados e tentar enviar a informação para C e B respectivamente, ou seja, agora C vai enviar para B e B para C, pois C partilha a mesma ligação que B e vice-versa. Quando eles recebem a segunda mensagem, C e B vão verificar que o número da mensagem é igual ao do registo da base de dados, logo eles já não vão fazer nada, nem actualizações, nem reenviar a mensagem, parando a “inundação”. Durante o mesmo período, B transmitiu o seu novo estado em relação ligação 1 para o nó C e E.
De B, para A, ligação 1,
distância=infinito, número=2
O protocolo de inundação (flooding) vai transportar esta actualização para D e depois para A, no fim do flooding as tabelas vão ter o seguinte aspecto:
|
De |
Para |
Ligação |
Distância |
Número |
|
A |
B |
1 |
inf |
2 |
|
A |
D |
3 |
1 |
1 |
|
B |
A |
1 |
inf |
2 |
|
B |
C |
2 |
1 |
1 |
|
B |
E |
4 |
1 |
1 |
|
C |
B |
2 |
1 |
1 |
|
C |
E |
5 |
1 |
1 |
|
D |
A |
3 |
1 |
1 |
|
D |
E |
6 |
1 |
1 |
|
E |
B |
4 |
1 |
1 |
|
E |
C |
5 |
1 |
1 |
|
E |
D |
6 |
1 |
1 |
É preciso ter em conta que os números sequenciais têm um problema, pois desde que o objectivo é manter a rede operacional por muito tempo, estes números tendem a ficar muito grandes, excedendo o número de bits que lhe são reservados nos pacotes e nos registos das bases de dados. Os protocolos geralmente usam a numeração “módulo de N”, ou seja, quando temos o número 4.294.967.295 em que N=32 (2 32-1) é 0, não 4.294.967.296. Tal espaço de número é circular; um precisa de uma convenção explicita para definir quando é que X é maior que Y.
Os números sequenciais são normalmente incrementados lentamente, ou seja, depois de uma transição de ligação ou excedido o tempo de vida. Assim se um nó precisa de executar um pequeno incremento a X para obter Y, então é realista adivinhar que Y foi enviado mais tarde que X, e vice-versa. Realmente, tem de ser definido o que é um “pequeno incremento”; também tem de se definir a comparação, para que todos os routers tenham a mesma versão de um registo. A convenção utilizada no OSPF foi sugerida por Radia Perlman em 1983, e é referida como o espaço de sequência “lollipop” (o chupa-chupa), que usa números de sequência com 32 bits.
2.2.3 Adjacências
Para ilustrar o conceito de adjacência, vamos considerar a figura 10, onde estamos perante uma separação da rede original em duas redes mais pequenas.
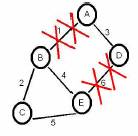
Figura 10: Separação de redes
Assim que acontece a separação, vamos passar a ter duas bases de dados diferentes (uma para A e D, outra para B, C e E), pois ambas vão evoluir separadamente devido ao sucedido. Como os nós vão ser capazes de computar imediatamente este novo estado de encaminhamento depois de receberem o novo estado da ligação, sem correrem o risco de entrarem na contagem-para-infinito.
Na rede dos nós B, C e E, mesmo que agora seja quebrada outra ligação a base de dados dos nós A e D já não sofre alterações, pois estão neste momento completamente separadas.
Agora suponhamos que a ligação número 1 está novamente operacional. As duas bases de dados diferentes, agora vão ter que entrar em conformidade, e para isso é necessário mais do que o envio de um simples registo de base de dados. Este processo de sincronizar as bases de dados é designado por bringing up adjacencies no OSPF.
O alinhamento das duas bases de dados é ajudado pelo uso de identificadores de ligação e números de versão. As duas partes têm de sincronizar as suas bases de dados e manter somente os registos com versão mais actualizada, ou seja o registo com maior número. Trocar cópias completas das bases de dados é um pouco ineficiente, pois os registos em ambas as bases de dados são muito similares, não sendo necessário enviá-los. O OSPF resolve este problema definindo pacotes de “database description” (descrição da base de dados), que contém somente os identificadores de ligação e os números de versão correspondentes.
Durante a
primeira parte do procedimento de sincronização, os routers vão enviar uma descrição completa dos registos das suas
bases de dados, numa sequência de pacotes de descrição. Quando recebem estes
pacotes, eles vão comparar os números de sequência com os que estão presentes
nas suas bases de dados, e constroem uma lista de “registos interessantes”,
quando o número remoto é maior que o número local, ou quando o identificador de
ligação não está presente na base de dados local. Na segunda parte do
procedimento de sincronização, cada router
vai pedir ao seu vizinho uma cópia dos registos que constam na lista de
registos interessantes, através de pacotes “link state request”.
Esta sincronização vai provocar actualizações nas bases de dados, estas actualizações têm de ser transmitidas para os restantes nós da rede, esse processo é feito pelo procedimento normal de inundação.
2.2.4 Segurança nas actualizações
É necessário proteger a base de dados onde são guardadas as rotas contra qualquer acção que as possa corromper. Na origem de acessos que podem corromper as tabelas de encaminhamento estão acidentes originários de uma falha tanto de procedimentos de inundação ou sincronização, ou de erros de memória, ou mesmo a introdução de informação proveniente de agentes com más intenções. O OSPF inclui um número de protecções contra estes perigos:
- O procedimento de inundação contém respostas hop-by-hop, ou seja, cada nó que recebe os vectores de distância, responde com um acknowledgment.
- Os pacotes de descrição da base de dados são transmitidos de um modo seguro.
- Cada registo possui um tempo de vida e esse registo é removido quando o tempo expira e ainda não chegou outro pacote.
- Todos os registos são protegidos por um checksum.
- As mensagens podem ser autenticadas, por exemplo, por passwords.
Um problema particular acontece quando um nó é colocado na rede logo depois de ter ocorrido uma falha. Este nó vai tentar inundar a rede com a sua versão dos registos de estado de ligação, começando com o número de sequência inicial. Se o tempo que o nó esteve inactivo foi pequeno, versões antigas dos registos dos nós ainda estão presentes na base de dados; o número deles parece mais novo e o nó vai receber uma cópia desses registos antigos. Para acelerar a convergência, o nó deve usar o número recebido, incrementá-lo, e retransmitir imediatamente os seus registos com este novo número.
O OSPFv3 (OSPF versão 3), é a versão do protocolo OSPF que suporta IPv6, este protocolo, tem um funcionamento muito similar ao seu antecessor de IPv4, somente contém as devidas modificações para suportar o novo protocolo IPv6.
Este protocolo com já foi referido anteriormente, é um protocolo do tipo link state. Cada router possui uma base de dados com a topologia da rede onde se insere, e usa o algoritmo de Dijkstra para calcular os percursos mínimos (short path). Essa base de dados é construída através da troca de informação necessária pelo procedimento de inundação referido na secção 2.2.2.
Este protocolo permite que um AS[3] (Autonomous System), seja dividido em áreas numeradas. Todos os AS contêm um backbone (área 0); todas as áreas existentes estão ligadas directamente ao backbone, e qualquer tipo de comunicação entre quaisquer áreas tem obrigatoriamente que passar por esse backbone. Assim podemos dizer que qualquer router que esteja ligado a mais que uma área faz parte desse backbone. Este tipo de funcionamento (hierarquizado) da rede tem por objectivo diminuir o tamanho das bases de dados dos routers e restringir o tráfego de controlo.
Como dividimos as nossas redes em áreas, e temos routers que pertencem ao backbone, e outros que pertencem a uma área específica, desta forma podemos dividir os routers em vários tipos diferentes:
- internos - pertencem apenas a uma área;
- de fronteira das áreas (ABR - Area Border Routers) - ligam duas ou mais áreas;
- de backbone - pertencem ao backbone;
- da fronteira dos Sistemas Autónomos} (ASBR - Autonomous System Border Routers).
Os Area Border Routers (ABR), como já referimos, têm as sua interfaces em duas ou mais áreas, como o OSPF diz que todos os nós têm de conter a topologia da rede numa base de dados interna, logo este tipo de routers têm um esforço adicional, pois são obrigados a conhecer a topologia de uma ou mais redes, consoante as áreas a que ele pertence. A um router interno, só lhe é “exigido” que conheça apenas a sua própria rede.
Numa mesma rede local é possível estarem ligados vários routers. Quando isto acontece, são eleitos dois deles, um para o “cargo” de DR (Designated Router) e o outro para BDR (Backup Designated Router). O BDR tem como função assumir o controlo se o DR ficar inoperacional, por este motivo tem de conter a mesma informação que o DR. Todos os routers existentes na mesma rede designam-se por vizinhos.
Existe sempre um DR, pois assim evita que todos os routers existentes na rede comuniquem uns com os outros, ou seja, comuniquem com todos os seus vizinhos. Assim em vez de um router comunicar com todos os seus vizinhos, cria adjacências (relações de amizade) com o DR e é com ele que comunica, logo o DR é o router responsável por transmitir a informação vinda do exterior da rede local aos seus vizinhos e de transmitir informação para fora da mesma, proveniente dos seus vizinhos. O DR pode ser visto com um representante de uma rede local.
Já sabemos o porquê da existência tanto do DR como do BDR, mas com se faz a escolha? É muito simples, normalmente o primeiro router a ser ligado numa sub-rede IP, fica como DR e o segundo como BDR. Após este método, a identidade destes só será alterada em caso de falha de um deles, se isso acontecer com o DR, o DR passará a ser o antigo BDR e o BDR passará a ser o router que, de entre os restantes ligados à rede, tem maior prioridade (em cada router OSPF pode ser configurada uma prioridade, tornando assim possível ao administrador determinar qual router será o DR e o BDR). Em caso de empate de prioridades, será escolhido o router com maior RID (Router ID - identifica um router e corresponde ao endereço IP mais elevado de todas as interfaces do router).
Falando agora a nível mais físico, a informação necessária para criar e manter as bases de dados é transportada sobre a forma de LSAs (Link State Advertisement). Existem quatro tipos de LSAs:
- Router Links – são gerados por todos os routers, e descrevem o estado das interfaces dele mesmo (dentro de uma determinada área), somente são difundidos dentro da área a que o router pertence;
- Network Links – são gerados
pelo DR e indicam quais os routers
ligados à rede a que o DR pertence;
- Summary Links – só ocorrem quando existe mais do que uma área, são gerados pelo ABR e listam as redes que pertencem a outras áreas, realiza-se através do backbone;
- External Links – só ocorrem quando existe ligação a outro SA, são gerados pelos ASBR.
Os pacotes LSAs contem ainda um campo designado por Link State ID, que assume significados diferentes consoante o tipo de LSA em que aparece. A tabela seguinte mostra em suma os significados que o Link State ID pode assumir.
|
Tipo de LSA |
Significado do Link State ID |
|
Router Links |
RID (Router ID)
do router que o originou |
|
Network Links |
Endereço IP da interface do DR ligada à rede a que se
refere o Network Link |
|
Summary Links |
Endereço da rede |
O primeiro protocolo de encaminhamento da família dos protocolos Link State, foi desenvolvido pela ISO (International Organization for Standards) e designado de IS-IS (Intermediate System to Intermediate System Intra-Domain Routeing Protocol), tendo como principal função de encaminhar pacotes de CLNP (Connectionless Network Protocol). Por esta altura a IETF (Internet Engineering Task Force) procurava um protocolo de encaminhamento da família Link State, que pudesse ser utilizado em IPv4.Desenvolveu-se um protocolo similar ao IS-IS com o nome OSPF (Open Shortest Path First).
À medida que o OSPF ia sendo especificado, o IS-IS foi extendido para suportar IPv4 no RFC 1195. Passaram alguns anos após a extensão do IS-IS, para que o OSPF, estivesse pronto, o que fez com que muitos ISP's (Internet Service Provider) adoptassem o IS-IS, enquanto os seus clientes usavam RIP nas suas redes.
Hoje em dia existe uma preferência maior no que diz respeito ao OSPF, sendo este o protocolo usado na maior parte das redes mundiais. Mesmo perante a supremacia do OSPF, o IS-IS tem vindo a ganhar adeptos, que em conjunto têm vindo a melhorar o IS-IS a fim de colmatar as lacunas deste e torna-lo num protocolo mais versátil e eficaz.
2.3.1 Bases do protocolo IS-IS
O protocolo de encaminhamento IS-IS, é parte integrante da estrutura de encaminhamento do OSI (Open Systems Interconnection). Essa estrutura é hierárquica, separando os domínios de encaminhamento em áreas, compondo numa ou várias redes locais. Este protocolo trabalha directamente no topo da camada de ligação, em paralelo com o CLNP[4].
Assim como no OSPF, todas as áreas são ligadas através de um backbone, ou seja, existe um “nível 2” no IS-IS que reúne todos os routers de backbone que é hierarquicamente superior ao “nível 1” (no interior das áreas). Uma área liga hosts a routers de “nível 1”, e são identificáveis por um número. Existe pelo menos um router na área que é simultaneamente do “nível 1” como do “nível 2”, ou seja, liga a área ao backbone, desempenhando um papel idêntico aos area border routers no OSPF. Esta divisão em áreas no protocolo IS-IS, é efectuada com mais rigidez que no seu “primo” OSPF. Outra das diferenças do IS-IS em relação ao OSPF, é a ausência de qualquer identificação de sub-redes na estrutura de encaminhamento OSI, pois o endereço no IS-IS inclui identificadores de áreas e sistemas, não de sub-redes ou redes locais (no OSPF a identificação de uma rede ou de um sistema, pode ser efectuada com o seu endereço IPv4). Uma consequência desta diferença é que os routers têm de manter explicitamente a “pista” da localização dos hosts dentro da área deles. Os hosts declaram-se para os routers conectados à sub-rede, através do End System to Intermediate System Routeing Protocol (ES-IS), e os routers descrevem estas adjacências nos registos \emph{link state} do IS-IS. Esta é a única informação detalhada que os routers de nível 1 mantêm, pois todos os pacotes que são para outras áreas ou domínios, são simplesmente passados para o router de nível 2 mais próximo, estes sim com mais algum conhecimento. O modelo hierárquico também se aplica para encaminhamento de nível 2, pois visto do backbone, todos os pontos de acesso para uma área são equivalentes. Pacotes que são para uma área são muitas vezes passados para o router de nível dois mais próximo que também pertence a essa área.
Uma consequência desta organização, é que se espera que as áreas permaneçam interligadas internamente, mas pode ocorrer fracturas numa área. A maneira de resolver estas fracturas é estabelecer um “túnel” através do
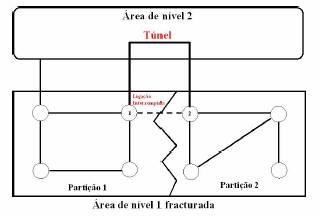
Figura 11: Túnel para resolução de fracturas em áreas
backbone, ou seja, em caso de uma área se separar em duas (através da quebra de ligações), qualquer router de nível dois conectado a essa área pode receber pacotes que têm como destino a outra metade da área, ele irá transmiti-lo através do backbone encapsulando-o num pacote para um router ligado à outra metade da área. É necessário frisar que esta técnica não pode ser utilizada para ligar novamente um backbone separado, neste caso simplesmente tem que se esperar que a conectividade seja restabelecida.
2.3.2 Sub-protocolos do IS-IS
Assim como o OSPF, o IS-IS contém alguns sub-protocolos. O protocolo Hello é usado para descobrir os vizinhos e eleger o Designated Router em ligações broadcast. O protocolo flooding (inundação) é usado para propagar os registos de estado de ligação (link state) dentro das áreas ou do backbone.
Nas ligações broadcast, os hellos do IS-IS transportam a identificação da fonte, o “tipo de circuito” que caracteriza o router como sendo de nível 1 ou de nível 2, ou de ambos, a prioridade e uma lista dos endereços das áreas a que pertence, a lista dos endereços dos outros routers que considera também ligados à rede local. A prioridade do router é configurada pelo administrador da rede, e o router que tiver maior prioridade é eleito designated router. Se dois routers tiverem a mesma prioridade, o que tiver maior identificador é o escolhido. A rede local é identificada por uma campo com sete bytes composto pelo identificador do designated router e por um selector assinado por este router.
O IS-IS na realidade possui quatro formas diferentes de pacotes hello, um para nível 1, outro para nível 2, para broadcasts e ligações ponto a ponto. Um broadcast pode ser partilhado entre routers de nível 1 e de nível 2. Haverá um designated router diferente em cada nível e diferente adjacência. Não existe qualquer tipo de designated router em ligações ponto a ponto.
Os pacotes hello são repetidos em intervalos regulares, e são usados para verificar a disponibilidade da ligação. Se dois routers concordarem que ambos pertencem à mesma área, a ligação vai ser reportada num aviso de nível 1, caso contrário, é reportada em nível 2.
2.3.3 Particularidades do IS-IS
Todos os registos LSP (Link State Protocol) contêm um identificador de 8 bytes (LSPID), composto por 48 bits do identificador de sistema, 1 byte pseudo-ID, e um número de registo (LSP number). O pseudo-ID é normalmente nulo, excepto quando um designated route o usa para identificar uma rede broadcast. Os registos têm tamanho limitado, se existir muita informação para caber num só registo, os routers constroem vários registos identificados por LSP number sucessivos. Cada um destes registos vai ser independentemente inundado (flooded). O primeiro registo da sequência deve incluir sempre a identificação das áreas a que o router pertence. Os registos de um router devem ser inundados somente nas áreas a que pertence o router.
Um registo na base de dados é qualificado por um número de sequência e um tempo de vida, em que o valor é caracterizado por um checksum. O número de sequência é um inteiro de 32 bits, que começa em 1 e é incrementado regularmente (o valor zero não é usado). Este protocolo não prevê um espaço de sequência “lollipop” (ver: 2.2), já que se o router estiver a trabalhar durante muito tempo, o número de sequência vai eventualmente chegar à sua capacidade máxima (32 bits), ai o router não terá outra hipótese se não fingir uma falha, e voltar a usar o número 1. Este tipo de cenário é muito improvável de acontecer com os 32 bits disponíveis, o router podia enviar um novo valor a cada segundo por mais de um século antes de atingir o máximo, por isso é que este protocolo utiliza comparação directa dos números de sequência.
No IS-IS o protocolo de flooding tem o mesmo objectivo que o do OSPF, mas é organizado de maneira diferente. Quando um router recebe um novo registo link state de um vizinho, ele compara o número de sequência com o que possui na sua base de dados, se o número de sequência do registo recebido é maior, ou se ainda não se encontra na base de dados, o router guarda-o na base de dados e marca-o para resposta (acknowledgment) ao
router que enviou o registo, e inundar para todos os restantes vizinhos. Se o número de sequência for menor, o router simplesmente ignora o valor recebido e mais tarde deve enviar ao vizinho que lhe enviou este registo, o que tem guardado na tabela, com número de sequência superior ao recebido. Se o número de sequência for igual, os checksums são comparados, se o resultado for igual tudo está bem e o registo é simplesmente marcado para resposta ao vizinho remetente. Se os checksums forem diferentes, significa erro, o que faz com que imediatamente expire o tempo de vida do registo armazenado.
Nas ligações de broadcast, como anteriormente referido, só o designated router envia mensagens periódicas, para que todos os vizinhos possam manter as suas bases de dados actualizadas com a do designated router, se um router que não é designado determinar que o designated router possui um registo desactualizado, simplesmente envia-o em multicast.
Quando aparece uma adjacência na rede que já existiu antes, os routers trocam mensagens de “número de sequência completo”. Este tipo de mensagens sumaria todos os registos da base de dados. O router que recebe a mensagem, compara este sumário com o que ele contém na sua base de dados, e anota os registos que estão em falta ou são muito velhos. Ele também marca os registos que contêm números de sequência mais baixo que os dele para flooding, já que ele contém na sua base de dados registos mais actualizados que os enviados.
As diferenças entre o IS-IS e o OSPF no que diz respeito ao procedimento de troca (bringing up adjacencies no OSPF) está de fato integrada no procedimento normal de flooding. Se o router recebe um identificador de um registo que não se encontra presente na base de dados local, ele anota-o para resposta com um número de sequência 0. Como todos os números de sequência são maiores que zero, isto vai “disparar” uma inundação do valor do registo pelo ponto. O router também anota para resposta todos os registos que o número sumariado é maior que o número presente na base de dados. Estas respostas serão repetidas em intervalos regulares até ser recebido um valor actualizado.
No que diz respeito ao tempo de vida dos registos das bases de dados, este é decrementado cada segundo, e quando atinge o valor zero, é anotado como inutilizado, mas permanece na base de dados durante mais 60 segundos, tempo este que é designado de ZeroAgeLifeTime.
2.3.4 Métricas no IS-IS
Os registos link state listam as áreas a que os routers pertencem, e as distâncias para os routers vizinhos e para os hosts ligados localmente no caso do nível 1. De fato, para cada host ou vizinho, quatro distâncias são listadas de acordo com as métricas de por defeito, atraso, gasto e erro. A métrica por defeito descreve as ligações throughput, a métrica de atraso, descreve o atraso de propagação, a métrica de gasto ou despesa, o seu custo financeiro, e a métrica de erro descreve a taxa de erro. Os valores aos caminhos são calculados através da soma destas métricas.

Figura 12: Exemplo de parte de um pacote do IS-IS
O bit I/E na métrica por defeito, é colocado a 1 para métricas externas maiores do que qualquer distância interna. O bit S nas restantes métricas é colocado a 1 no caso de a métrica não ser suportada. É de notar que existem somente seis bits disponíveis nos pacotes para representar o valor da métrica (este valor é muito menor que o do OSPF). Estes campos são mesmo uma das limitações do IS-IS, pois dado ao seu reduzido tamanho, não se pode ter muita precisão em métricas, ou seja, se tivermos uma rede com ligações a funcionar a 45-Mbps e a 64-Mbps, uma é 700 vezes mais rápida do que a outra, mas a escala permite no entanto somente 31 posições (devido aos 6 bits).
Capítulo 3
O GNU Zebra é um software de encaminhamento open source, distribuído sob a Licença Pública Geral (GPL). O zebra suporta um número de protocolos de encaminhamento baseados em TCP/IP, cada um independente do outro funcionando separadamente. Este software foi desenvolvido de modo a que seja possível ser executado sobre uma variedade de sistemas operativos, entre os quais se destacam, freeBSD, GNU/Linux e plataformas Solaris.
Na tabela seguinte podemos verificar os protocolos de encaminhamento e respectivos daemons implementados no Zebra:
|
Protocolo |
Nome do Daemon |
|
BGP-4 e BGP-4+ |
bgpd |
|
RIPv1 e RIPv2 |
ripd |
|
RIPng |
ripngd |
|
OSPFv2 |
ospfd |
|
OSPFv3 |
ospf6d |
|
ISIS |
isisd |
|
Zebra |
zebra |
Cada um destes protocolos usa o socket básico API para receber e transmitir os pacotes específicos a cada protocolo. Apesar de trabalharem independentemente uns dos outros, os daemons estão interligados ao Zebra através do protocolo Zebra. O processo Zebra passa a informação de encaminhamento para o kernel.
Durante as experiências práticas foi usada a versão (0.93a) [3] do Zebra. O processo de instalação do Zebra tem início com a descompactação do ficheiro zebra-0.93a.tar.gz, usando o comando:
tar -zxvf zebra-0.93a.tar.gz
Desse processo resultou uma directoria (zebra-0.93a), dentro dessa directoria zebra-0.93a, consultamos o ficheiro INSTALL que contém informações acerca do processo de instalação do pacote de software Zebra.
Seguindo os passos descritos no ficheiro, iniciámos a instalação com o comando ./configure executando-o dentro da pasta onde nos localizámos anteriormente. Este comando executado, vai preparar todos os ficheiros necessários de modo a serem compilados. Depois do ./configure, executámos o make, este sim vai compilar
os ficheiros respectivos. O processo demora um pouco, e assim que esteja concluído podemos executar o make install (coloca os ficheiros compilados nas directorias certas). Para finalizar os comandos de instalação do Zebra, utilizámos o make clean para “limpar” o “lixo” criado pelos comandos anteriores. No final, podemos apagar os ficheiros de instalação, e a respectiva directoria, para isso subimos um nível na árvore de directorias
(cd ..) e executamos o comando rm -Rf zebra-093a* para remover totalmente a directoria e ficheiros nela contidos.
3.3 Configuração do Zebra IPV4
Como a nossa experiência a nível de Zebra era praticamente nula, decidimos começar este projecto pela configuração básica do Zebra com alguns protocolos de encaminhamento, afim de adquirir-mos algum à vontade, antes de passarmos ao IPv6 (ver: 1). Para esse efeito foi montada a rede da figura 13.
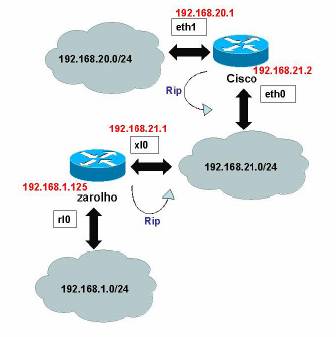
Figura 13: Rede usada em testes ipv4
Nessa rede usámos um pc (Zarolho) com o freeBSD Release: 4.7} [10] como sistema operativo, a “correr” Zebra e rip, e um router da Cisco Série 1600, para podermos testar a transacção de pacotes rip e respectivo encaminhamento. Para este teste além dos routers, temos também implementado três redes (a 1,21,20), para colocarmos um pouco de complexidade nas situações testadas.
Para a configuração do router (Zebra, em IPv4), entramos na directoria /usr/local/etc onde se encontram os samples do zebra (*.conf.samples). Para que o daemon do Zebra ou de um protocolo de encaminhamento seja executado, é necessário a presença dos ficheiros .conf onde estão os parâmetros de configuração. Para o Zebra funcionar, fazemos uma cópia do ficheiro do Zebra zebra.conf.sample (ou de outro qualquer lá existente, dependendo do que quisermos utilizar), com o nome de zebra.conf, para que o daemon obtenha nesse ficheiro as configurações mínimas de funcionamento, de forma a que apenas execute sem quaisquer tipos de funções atribuídas.
No ficheiro zebra.conf onde diz hostname podemos colocar o nome do serviço (router) afim de nos facilitar a distinção entre o ambiente do sistema operativo e o ambiente do próprio zebra (pois este hostname vai ser a prompt) quando estamos em modo vty. Em password colocamos a password de acesso ao serviço Zebra através de telnet. Se desejarmos segurança adicional podemos ainda alterar em enable password, onde colocamos a password que permite aceder ao modo privilegiado (permite a configuração do router).
Após termos alterado as opções facultativas anteriormente mencionadas, podemos então dar início ao Zebra (zebra -d -> Para correr em daemon mode).
De seguida, para configurar o router, temos de iniciar uma sessão telnet através do porto 2601 (telnet localhost 2601), onde vamos entrar em modo vty. A partir deste momento o interface é semelhante ao de um router da Cisco Série 1600.
No que diz respeito à configuração do zebra para que a seja possível a conectividade entre as redes, seguimos os seguintes procedimentos:
telnet localhost 2601
router> enable (entrar em modo privilegiado)
(para modo auto-complete pressionar a tecla "tab")
router# configure terminal (Entrar em modo de configuração)
router(config)# interface rl0 (configurar o interface rl0)
router(config-if)# ip address 192.168.1.125 255.255.255.0 (rede alcançada pela
interface)
router(config-if)# no shutdown (para a interface não ir a baixo)
router(config-if)# exit (voltar a trás)
router(config)#interface xl0 (configurar o interface xl0 se for
necessário)
router(config-if)# ip address 192.168.21.1 255.255.255.0 (rede alcançada pela
interface)
router(config-if)# no shutdown (para o interface não ir a baixo)
router(config-if)# end
router# write (grava as configurações no startup-config(zebra.conf))
router# exit (termina a sessão telnet)
A configuração do Cisco, é muito semelhante à anterior, como podemos verificar de seguida. Para podermos configurar o router da Cisco série 1600, também podemos aceder a este através de telnet, mas por questões de segurança devemos usar a porta com de um pc para configuração do router, através de hiper terminal disponibilizado pela Microsoft no pacote Windows. Após estarmos conectados ao router seguimos os seguintes passos:
Router> enable (entrar em modo privilegiado)
(para modo auto-complete pressionar a tecla "tab")
Router# configure terminal (Entrar em modo de configuração)
Router(config)# interface ethernet 0 (configurar o interface rl0)
Router(config-if)# ip address 192.168.21.2 255.255.255.0 (rede alcançada pela
interface)
Router(config-if)# no shutdown (para a interface não ir a baixo)
Router(config-if)# end (voltar a trás)
Router# configure terminal (Entrar em modo de configuração)
Router(config)# interface ethernet 1 (configurar o interface rl0)
Router(config-if)# ip address 192.168.20.1 255.255.255.0 (rede alcançada pela
interface)
Router(config-if)# no shutdown (para a interface não ir a baixo)
Router(config-if)# end
Router#
write (grava as configurações no startup-config)
Router# exit
Após esta configuração estar concluída, ainda não é o suficiente para estabelecer a conectividade entre as redes existentes, pois ambos os routers ainda não têm conhecimento das rotas para que seja possível a uma máquina na rede 1 comunicar com outra na rede 20. Para que isso seja possível podemos adicionar rotas estáticas ou usar um protocolo de encaminhamento, para que os routers possam trocar entre si as rotas que conhecem sem intervenção do administrador.
Para a introdução de uma rota estática, no router da Cisco, podemos usar os seguintes comandos:
Router> enable (entrar em modo privilegiado)
(para modo auto-complete pressionar a tecla "tab")
Router# configure terminal (Entrar em modo de configuração)
Router(config)# ip route 192.168.1.0 255.255.255.0 192.168.21.1 (rota
estática)
Router(config)# end
Router# write
Para fazer o mesmo no zebra é só fazer:
Router> enable (entrar em modo privilegiado)
(para modo auto-complete pressionar a tecla "tab")
Router# configure terminal (Entrar em modo de configuração)
Router(config)# ip route 192.168.20.0 255.255.255.0 192.168.21.2
Router(config)#
end
Router#
write
Agora já existe conectividade entre as redes existentes.
Se em vez de utilizarmos rotas estáticas, podemos facilitar usando um protocolo de encaminhamento, para isso criamos rotas dinâmicas através do protocolo RIP (ver: 2.1). Para colocar o RIP a funcionar no zebra, basta copiar na directoria /usr/local/etc o ficheiro ripd.conf.sample para ripd.conf afim deste trabalhar nas configurações mínimas. No ficheiro ripd.conf podemos configurar as passwords tal como fizemos para o ficheiro
zebra.conf. Quando efectuarmos as alterações necessárias no rip.conf, podemos dar início ao RIP com o comando ripd –d (-d para que execute em daemon mode). Para o RIP funcionar, temos de o configurar, para isso tem que se iniciar novamente uma sessão de telnet, mas desta vez utilizando o porto 2602 (telnet localhost 2602).
Após colocada a password de início de sessão, damos início à configuração das redes e interfaces. Passos a seguir (em linha de comandos) para a configuração do RIP:
ripd> enable (entrar em modo privilegiado)
(para modo auto-complete pressionar a tecla "tab")
ripd# configure terminal (Entrar em modo de configuração)
ripd(config)# router rip (activar o modo RIP)
ripd(config-router)# network 192.168.1.0 (rede alcançada)
ripd(config-router)# network rl0 (interface associado à rede)
ripd(config-router)# network 192.168.21.0
ripd(config-router)#
network xl0
ripd(config-router)#
end
ripd#
configure terminal
ripd(config)# interface rl0 (configurar interface)
ripd(config-if)# ip rip send version 2 1 (o interface rl0 passa a enviar
RIP's da versão 1 e 2)
ripd(config-if)# ip rip receive version 2 1 (o interface rl0 passa a
receber RIP's da versão 1 e 2)
ripd(config-if)# end
ripd#
configure terminal
ripd(config)# interface xl0 (configurar interface)
ripd(config-if)# ip rip send version 2 1 (o interface xl0 passa a enviar
RIP's da versão 1 e 2)
ripd(config-if)# ip rip receive version 2 1 (o interface xl0 passa a
receber RIP's da versão 1 e 2)
ripd(config-if)# end
ripd#
write (grava as configurações no startup-config(ripd.conf))
ripd# exit (termina a sessão telnet)
Apesar das semelhanças até agora mantidas entre a configuração do Zebra e do router da Cisco, no que diz ao rip já existem diferenças, no router da Cisco é muito mais simples colocar o RIP m funcionamento como podemos verificar de seguida:
Router> enable (entrar em modo privilegiado)
(para modo auto-complete pressionar a tecla "tab")
Router# configure terminal (Entrar em modo de configuração)
Router(config)# router rip
Router(config-router)# network 192.168.21.0
Router(config-router)# network 192.168.20.0
Router# write
Router# end
Com estas configurações os routers passam a trocar mensagens de RIP, onde transportam a informação das rotas que conhecem, e ao receberem as mensagens um do outro vão actualizar as suas tabelas de encaminhamento. Nas figuras 14 e 15, podemos observar a estrutura de um pacote RIP versão um e dois capturado na rede.
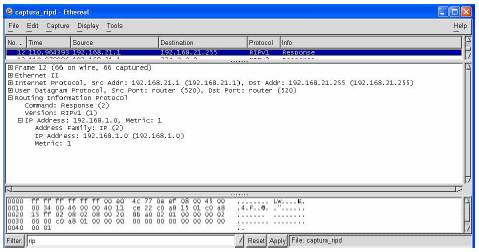
Figura 14: Pacote RIP versão 1
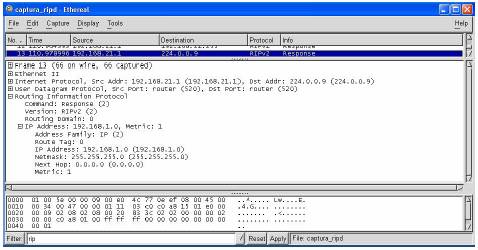
Figura 15: Pacote RIP versão 2
3.4 Configuração do Zebra IPV6
Agora que já percebemos mais alguma coisa do Zebra, vamos avançar para ambientes IPv6. Para testar-mos as nossas situações em IPv6, decidimos começar por uma rede bastante idêntica à anterior, podemos verificar as semelhanças entre as redes na figura 16, com as devidas mudanças para funcionar em IPv6.
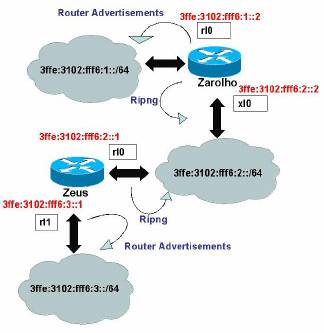
Figura 16: Rede para implementação IPv6
Como o IOS do router da Cisco não suporta IPv6, tivemos que recorrer a outro router implementado num pc com FreeBSD (Zeus) “correndo” o Zebra. De seguida vamos verificar as mudanças na configuração de um ambiente de IPv6 para IPv4, que não são muito distantes uma da outra. Como já verificámos anteriormente na configuração, estabelece-se uma ligação por telnet à porta 2601 afim de configurar o Zebra. Seguidamente configurámos o zarolho com os seguintes passos:
router> enable (entrar em modo privilegiado)
(para modo auto-complete pressionar a tecla "tab")
router# configure terminal (Entrar em modo de configuração)
router(config)# interface rl0 (configurar o interface rl0)
router(config-if)# ipv6 address 3ffe:3102:fff6:1::2/64 (rede alcançada pela
interface)
router(config-if)# no shutdown (para o interface não ir a baixo)
router(config-if)# exit (voltar a trás)
router(config)#interface xl0 (configurar o interface xl0 se for
necessário)
router(config-if)# ipv6 address 3ffe:3102:fff6:2::2/64 (rede alcançada pela
interface)
router(config-if)# no shutdown (para o interface não ir a baixo)
router(config-if)# end
router#
write (grava as configurações no startup-config(zebra.conf))
router# exit (termina a sessão telnet)
Assim já existe possibilidade de encaminhamento dos pacotes nas redes adjacentes ao nosso router, ou seja, nas redes dos interfaces rl0 e xl0. Para a configuração do outro router (Zeus) basta seguir os mesmos passos que para o anterior, com a diferença nos endereços (rl0 - 3ffe:3102:fff6:2::1, rl1 - 3ffe:3102:fff6:3::1).
Para a configuração dos routers advertisements (ver: 1), inicia-se uma sessão telnet
(telnet localhost 2601) para se configurar os advertisements, pois estes encontram-se no daemon do Zebra. Para isso seguem-se os passos anteriormente descritos até nos encontrarmos no modo privilegiado, ai faz-se:
Router> enable (entrar em modo privilegiado)
(para modo auto-complete pressionar a tecla "tab")
Router# configure terminal (Entrar em modo de configuração)
Router(config)# interface rl0 (para configurar a interface rl0)
Router(config-if)# ipv6 nd send-ra (indica que deve enviar router
advertisement)
Router(config-if)# ipv6 nd prefix-advertisement <prefixo da rede> (para
anunciar qual o prefixo que os clientes devem adoptar ex:
3ffe:3102:fff6:1::/64)
É ainda possível de configurar os tempos de envio e de vida de router advertisement no Zebra com os comandos ra-interval (para o período de envio) e ra-lifetime (para o tempo de vida dos advertisements). Após aplicar estas opções em ambos os routers com as devidas especificações conforme na figura 16, estão agora aptos a enviar os routers advertisements para as respectivas redes. Na figura 17 podemos observar o aspecto de um router advertisement.
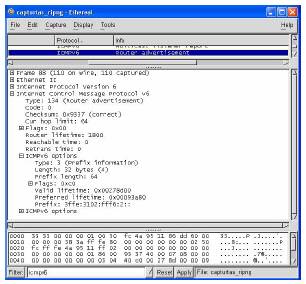
Figura 17: Router
Advertisement
Como podemos ver pela figura 16, existem anúncios de RIPng (ver: 2.1), para a rede dois que é onde estão as interfaces dos routers por onde eles vão comunicar. Para existir a comunicação entre os routers, temos como já realizámos em IPv4, que configurar o RIP.
Aqui é também necessário fazer o arranque do daemon com o comando ripdng -d (-d para que execute em daemon mode). Mais uma vez, é necessário dar início a uma sessão telnet (telnet localhost 2603) para a configuração. Muito similar ao RIP em IPv4, a configuração do RIPng no router Zarolho faz-se nos seguintes passos:
ripng> enable (entrar em modo privilegiado)
(para modo auto-complete pressionar a tecla “tab”)
ripng# configure terminal (Entrar em modo de configuração)
ripng(config)# router ripng (para permitir o RIPng)
ripng(config-router)# network 3ffe:3102:fff6:2::2/64 (rede para onde
irão ser enviados os ripng's)
ripng(config-router)# network xl0 (interface por onde serão enviados os
ripng's)
ripng(config-router)#
route 3ffe:3102:fff6:1::/64
ripng(config-router)#
route 3ffe:3102:fff6:2::/64
ripng(config-router)#
end
ripng#
write (grava as configurações no startup-config(ripng.conf))
ripng#
exit (termina a sessão telnet)
Com esta configuração o nosso router (zarolho) irá enviar RIP's pela interface rl0 para a rede de prefixo 3ffe:3102:fff6:2::/64. As mensagens de RIPng irão conter as redes que ele consegue “atingir” e respectivas métricas[5] (essas redes são especificadas na instrução route exemplificado anteriormente). Para a configuração do router Zeus, basta seguir os mesmos passos com a excepção de que os endereços diferem (ter atenção à rede da figura 16). Na figura 18 podemos observar a estrutura de um pacote RIPng.
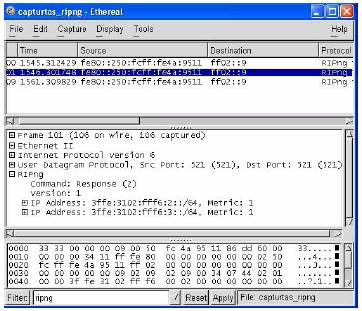
Figura 18: Pacote RIP next generetion
3.5 Ligação à FCCN utilizando RIPng
Para efectuar a ligação pretendida à FCCN (Fundação para a Computação Científica Nacional), usámos a rede da figura 16 implementada anteriormente mas com algumas modificações (ver figura 19) devido à necessidade da utilização de um túnel (ver: 3.6), sobre a rede pública em IPv4.
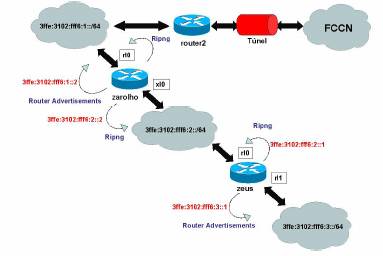
Figura 19: Rede de ligação à FCCN utilizando RIPng
Para a concretização desta implementação, foi necessário juntar mais um router (router2) para realizar o túnel, com extremo do lado da FCCN, de modo a mantermos o número de redes já configuradas.
O novo router da nova estrutura de rede, tem de ter uma configuração que segue a configuração dos outros routers, no que diz respeito ao Zebra e ao RIPng, ficando este a enviar anúncios (de RIPng), tanto para a rede 1 (para trocar rotas com o zarolho), como para o interior do túnel.
No que diz respeito a configurações, a configuração do router2 difere somente na parte do túnel, tanto no RIPng, como na criação do próprio túnel. Para a criação do túnel em IPv6, criámos um ficheiro executável no FreeBSD, com o seguinte conteúdo:
ifconfig gif0 create
gifconfig gif0 inet 193.139.65.223 134.136.25.257
ifconfig gif0 up
ifconfig gif0 inet6 3ffe:31ff:0:ffff::41
3ffe:31ff:0:ffff::40 prefixlen 128
route add -inet6 default -interface
3ffe:31ff:0:ffff::41
A interface que foi criada
(gif0), é uma interface virtual existente no FreeBSD, que permite a criação de túneis explícitos. A essa
interface vamos atribuir-lhe dois endereços, um em IPv4 (para fazer de extremo
do túnel em IPv4), que já está associado a uma interface física, e um IPv6
virtual, que vai servir de comunicação em IPv6 com o outro extremo do túnel.
Assim na gif0 temos os endereços 193.139.65.223 e 3ffe:31ff:0:ffff::41 que vão comunicar com 134.136.25.257
e 3ffe:31ff:0:ffff::40. A linha route
add -inet6 default -interface 3ffe:31ff:0:ffff::41 é uma rota estática que vai
enviar para o túnel todos pacotes IPv6 que não sejam destinados a ele ou que
sejam destinados à sua interface virtual. Para que o RIPng envie os seus
anúncios para o interior do túnel, basta configurá-lo para enviar os anúncios
para o endereço IPv6 virtual da gif0. A configuração para o lado interno da
nossa rede, segue a configuração normal já especificada.
Nesta configuração não recebemos as tabelas de encaminhamento da FCCN, devido à impossibilidade por parte dos routers da FCCN de implementar RIPng no túnel.
Dois routers IPv6/IPv4 interligam nós IPv6 através de uma infra-estrutura IPv4 como podemos observar na figura 20. As extremidades do túnel criam uma ligação lógica entre a origem e o destino. O túnel de IPv6 sobre IPv4 entre dois routers funciona como um único salto (contando apenas uma vez para o campo hop limit, independentemente do número de nós entre a origem e o destino). Todos os caminhos dentro de uma infra-estrutura IPv6 vão dar ao router IPv6/IPv4 da outra extremidade do túnel.
Figura 20: Túnel IPv6
Para testarmos
o protocolo IS-IS, recorremos a uma versão diferente do Zebra [3], a versão 0.93b-isisd-0.0.7
(zebra-0.93b-isisd-0.0.7).
O IS-IS é protocolo de encaminhamento da família link sate (ver: 2.3), que pretendemos implementar na estrutura da figura 16. Apesar das limitações do IS-IS em IPv6, testámo-lo para observar quais as funcionalidades implementadas no daemon até ao momento.
Para dar início ao daemon do IS-IS faz-se: isis -d. Para configurar abre-se uma sessão telnet (telnet localhost 2607), e seguidamente executam-se os seguintes passos:
Configurar uma nova área:
isisd> enable (entrar em modo privilegiado)
isisd# configure terminal (Entrar em modo de configuração)
isisd(config)# router isis <nome da nova área>
isisd(config-router)# net <Network Entity
Titles> (num dos routers
colocou-se: 49.0001.0001.0002.0023.00, no outro colocou-se : 49.0001.
0001.0002.0004.00 Ele identifica como a área o 49.0001 e como host
0001.0002.0004)
isisd(config-router)# is-type <nível de
operação> (level-1,
level-2-only e level-1-2 )
isisd(config-router)# end
De seguida coloca-se o IS-IS em funcionamento da seguinte forma:
isisd# configure terminal (Entrar em modo de configuração)
isisd(config)# interface <nome da interface a configurar>
isisd(config-if)# ipv6 router isis <nome da área anteriormente
configurada> (assim o ISIS começa a enviar os hello,
para ele enviar as rotas das duas interfaces, à que realizar
estes últimos passos para ambas as interfaces)
isisd(config-if)#end
isisd#
write
isisd# exit
Com as configurações anteriores nos respectivos routers, estamos perante um IS-IS a funcionar num modo básico (podemos ver pelas figuras 21, 22 e 23} a estrutura dos pacotes do IS-IS) pois devido às suas limitações em IPv6, não nos permite melhor controlo sobre o daemon. Um dos maiores problemas encontrados no daemon do IS-IS, é que sempre que reiniciamos o daemon, é necessário configurá-lo de novo pelo ambiente vty, dado que ele rejeita o .conf, reclamando mesmo erro.
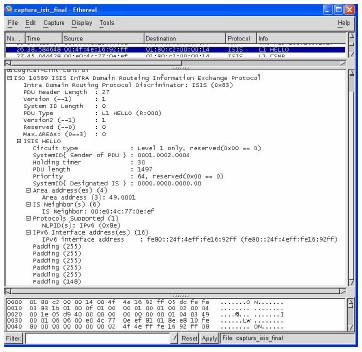
Figura 21: Pacote IS-IS Hello
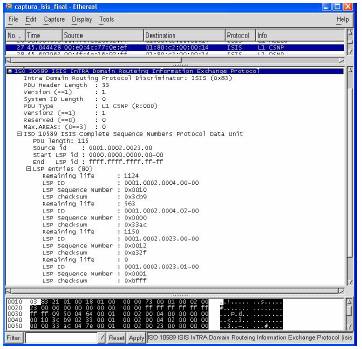
Figura 22: Pacote IS-IS CSNP
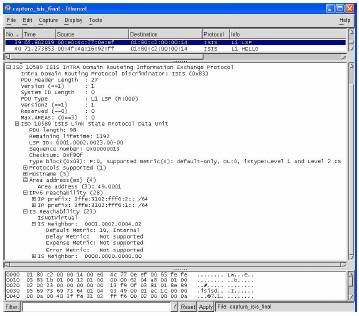
Figura 23: Pacote IS-IS LSP
3.8
Ligação
à FCCN utilizando OSPFv3
Apesar de ser
impossível a ligação à FCCN através do protocolo RIPng (ver: 3.7), optámos por
utilizar OSPFv3 dado que na FCCN já lhes era possível estabelecer contacto
através desse protocolo de encaminhamento. Neste caso vamos utilizar a rede com
a estrutura semelhante à utilizada na secção 3.5, mas dado as particularidades
do OSPFv3 (ver: 2.2), vimo-nos forçados a realizar algumas alterações como
podemos verificar na
figura 24.
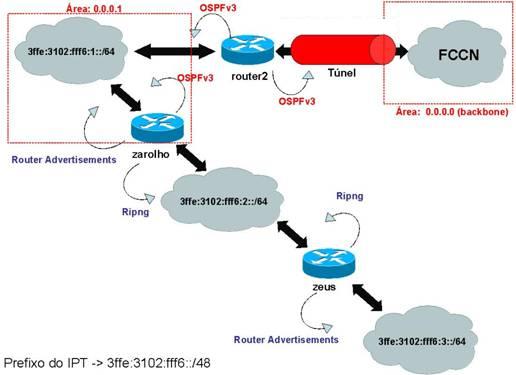
Figura 24: Rede de ligação à FCCN utilizando OSPFv3
Para que este cenário funcione temos que proceder às configurações dos respectivos routers que vão trabalhar com o OSPFv3, e do túnel em si dado que alguns endereços mudaram na extremidade da FCCN.
Na directoria /usr/local/etc copia-se o ficheiro ospf6d.conf.sample para ospf6d.conf, para que se possa dar início à configuração do protocolo. Edita-se o ficheiro ospf6d.conf, e apaga-se tudo o que diz respeito a interfaces, a ipv6 prefix-list hostroute... e tudo o que se encontra para baixo dessa linha. Após a edição do .conf inicia-se o daemon: ospf6d -d e abre-se uma sessão telnet (telnet localhost 2606) logo de seguida. Nessa sessão executa-se os seguintes passos:
ospf6d> enable
ospf6d# configure terminal (Entrar em modo de configuração)
ospf6d(config)# router ospf6
ospf6d(config-ospf6)# router-id <router id> (por defeito está 0.0.0.1,
só se altera caso seja necessário)
ospf6d(config-ospf6)# interface <nome da interface> area <id da área>
(usa-se também como no router-id, em formato IPv4 ex:0.0.0.2)
ospf6d(config-ospf6)# exit
ospf6d(config)# interface <nome da interface para a qual se quer activar
o OSPF>
ospf6d(config-if)# ipv6 ospf6 cost <custo> (valor por defeito é 1)
ospf6d(config-if)# ipv6 ospf6 hello-interval <tempo em segundos>
ospf6d(config-if)# ipv6 ospf6 dead-interval <tempo em segundos> (este é o
tempo de vida que o registo irá ter na tabela de encaminhamento, por isso
deve ser superior ao hello-interval afim de compensar eventuais atrasos
na rede)
ospf6d(config-if)# ipv6 ospf6 retransmit-interval <tempo em segundos>
ospf6d(config-if)# ipv6 ospf6 priority <prioridade em unidades> (
coloca-se de acordo com a estrutura da rede, pois é esta tag que
possibilita o controlo manual do Designated Router)
ospf6d(config-if)# ipv6 ospf6 transmit-delay <tempo em segundos>
ospf6d(config-if)# ipv6 ospf6 instance-id <id da ligação> (Se o outro nó
tiver um id de ligação diferente eles não vão comunicar, por isso ambos
os nós têm de ter o mesmo id. o \emph{default} é 0)
ospf6d(config-if)# exit
ospf6d(config)#
router ospf6
ospf6d(config-ospf6)# redistribute ripng (para traduzir as tabelas de RIP
em OSPF)
ospf6d(config-ospf6)# redistribute connected (para distribuir as rotas
directamente conectadas)
ospf6d(config-ospf6)# redistribute static (para distribuir as rotas
estáticas)
ospf6d(config-ospf6)#
end
ospf6d#
write
ospf6d# exit
Aplicando
estas configurações respeitando a estrutura da figura 24, estamos com a rede
pronta a funcionar. Se por ventura, tivermos uma rede mista (RIP,OSPF, que é o
nosso caso), temos que configurar o RIPng em router ripng. Quando estivermos em router ripng, tem de se executar o comando redistribute ospf6, para que este converta as tabelas de OSPFv3 em
formato RIPng, no OSPF como foi descrito anteriormente, faz-se
redistribute ripng. O router que estiver a trabalhar com os dois protocolos (RIP,OSPF) tem de estar a executar os dois daemons, tanto do ospf6d -d, como o do ripngd -d, para que funcione.
Após as configurações dos vários routers envolvidos no cenário (excepto a parte de OSPF que entra em contacto com o túnel) da figura 24, vamos proceder à construção do túnel como já aviamos feito. Como os parâmetros mudaram, o ficheiro de configuração do túnel do router2 vai ficar com o seguinte aspecto:
ifconfig gif0 create
gifconfig gif0 inet 193.139.65.223 134.136.25.257
ifconfig gif0 up
ifconfig gif0 inet6 2001:690:810:b::2
2001:690:810:b::1 prefixlen 128
route add -inet6 default -interface
2001:690:810:b::2
Agora com o túnel criado e com a rota estática activa, vamos configurar a parte que falta do OSPF no router2, para isso temos que enviar todos os anúncios de OSPF que devem ser dirigidos para o backbone (área 0.0.0.0) para a interface gif0. Para que isso aconteça, configuramos a interface gif0 da seguinte forma:
...
ospf6d(config-ospf6)#
interface gif0 area 0.0.0.0
...
ospf6d(config)#
interface gif0
ospf6d(config-if)#
ipv6 ospf6 cost 1
ospf6d(config-if)#
ipv6 ospf6 hello-interval 20
ospf6d(config-if)#
ipv6 ospf6 dead-interval 80
ospf6d(config-if)#
ipv6 ospf6 retransmit-interval 5
ospf6d(config-if)#
ipv6 ospf6 priority 1
ospf6d(config-if)#
ipv6 ospf6 transmit-delay 1
ospf6d(config-if)#
ipv6 ospf6 instance-id 0
ospf6d(config-if)# exit
...
Após esta configuração temos os anúncios e a troca de rotas entre o router2 e o router da FCCN a serem realizadas pelo túnel criado. Nas figuras 25, 26 e 27 podemos observar alguns pacotes usados durante a transacção no túnel.
Uma situação com que nos deparámos foi que, existia um problema no Area Border Router (ver: 2.2) pois este não enviava as rotas internas para a FCCN, e não anunciava aos routers internos (zarolho), que ele deveria ser o gateway deles. Na tentativa de resolução do problema, configurámos o router2 para que distribuísse as rotas de kernel, mas queríamos que acontecesse somente para o interior, mas por descuido nosso, o router2 distribuiu essas rotas para o túnel fazendo com que os routers da FCCN se baralhassem e fossem mesmo a baixo.
Na segunda tentativa, conseguimos solucionar o problema, para isso editámos o ficheiro /etc/rc.conf do zarolho e adicionámos a seguinte linha:
ipv6_defaultrouter="3ffe:3102:fff6:1::1"
Esta linha vai informar o zarolho de que todos os pacotes que ele receber e não souber qual é o seu destino, envia para o endereço 3ffe:3102:fff6:1::1, que por sinal é o endereço da interface rl1 do router2, ou seja, o router2 é o gateway do zarolho. Para que tudo funciona-se como previsto, no RIPng do zarolho (já que este funciona com OSPF e RIPng), executámos o comando redistribute kernel, para que este informasse o zeus, que sempre que não conhecer uma rota para enviar o pacote para ele. Desta forma, como o router2 era portador de todas as rotas externas à rede provenientes da FCCN, tinha-mos conectividade para todo o mundo ligado à FCCN.
Do nosso lado estava tudo completo e a funcionar como previsto, mas ainda residia um problema, pois o router da FCCN, não recebia as rotas da nossa rede. Após algumas tentativas de resolução do problema, fomos informados pelo senhor Yasuhiro Ohara através mailing list do zebra em zebra@zebra.org, que as funções de Area Border Router ainda não tinham sido implementadas, o que fazia com que chegássemos ao fim desta implementação.
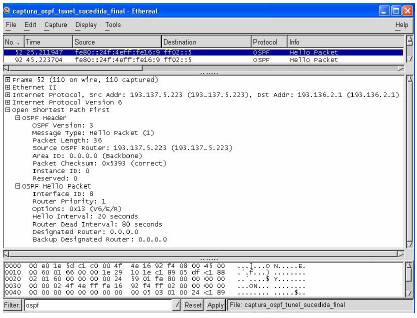
Figura 25: Pacote OSPFv3 Hello
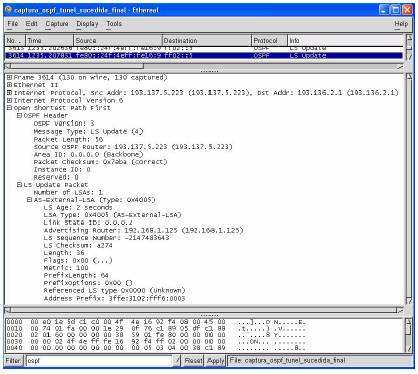
Figura 26: Pacote OSPFv3 LS Update
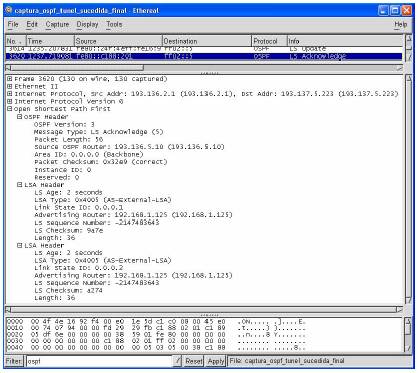
Figura 27: Pacote OSPFv3 LS Acknowledge
Capítulo 4
Para testar os
diferentes protocolos de encaminhamento, foram concebidos vários cenários nos
quais se pretende estudar o seu comportamento. Os cenários envolvidos e os
protocolos de encaminhamento usados, foram concebidos de forma a reflectirem
situações prováveis de acontecerem em redes controladas por uma única
organização.
Os cenários
foram adaptados de acordo com o protocolo de encaminhamento que pretendíamos
testar. Apesar de existirem cenários distintos para cada protocolo, também
realizámos testes onde foi usado mais do que um protocolo de encaminhamento,
por exemplo RIPng e OSPFv3 possibilitando desta forma o estudo da coabitação de
diferentes protocolos de encaminhamento.
Ao longo dos
trabalhos práticos foram encontrados diversas falhas de implementação dos
protocolos em estudo que estão na origem de comportamentos que não obedecem às
normas.
Dos três
protocolos de encaminhamento testados, o RIPng, neste momento, encontra-se mais
estável uma vez que é o que segue mais fielmente a norma que o define.
Na versão que foi usada para
testar o IS-IS não estão ainda disponíveis a maior parte das suas
funcionalidades. O OSPFv3 peca na sua maior virtude, ou seja na divisão de
áreas, por falta de implementação das funções que permitem que um router trabalhe em duas ou mais áreas
simultaneamente (Area Border Router).
Devido às
implementações disponíveis para cada um dos protocolos de encaminhamento
testado, o RIPng foi o que apresentou maior estabilidade.
Futuramente gostaríamos de implementar estes protocolos num cenário real, assim como numa futura rede do Instituto Politécnico de Tomar.
[1] Christian Huitema. Routing in the
Internet. Prentice Hall PTR, 2000. Segunda Edição.
[2] Sampo Saaristo. Implementation of IS-IS Routing Protocol for
IPversions 4 and 6. Master of
Sciense Thesis, 2002.
[3] Kunihiro Ishiguro. GNU Zebra
routing softweare. http://www.zebra.org Agosto
de 2002.
[4] Kunihiro Ishiguro. A routing
software package for TCP/IP networks, Zebra version 0.93b. Setembro de
2002.
[5] Cisco IOS Learning Services. The ABCs of IP Version 6.
[6] Cisco Systems. Open Shortest Path First v3.
[7] TechTarget. SearchNetworking.com.
http:// searchnetworking.techtarget.com Julho de 2003.
[8] Greg Wetzel. ISO Standards
On-Line. http://www.acm.org/sigcomm/standards/iso_stds/, Julho de 2003.
[9] FCCN. Fundação para a Computação Científica Nacional. http://www.fccn.pt/projectos/ipv6, 2001.
[10] FreeBSD. FreeBSD:The Power To
Serve. http://www.freebsd.org/. Junho de 2003.
Anexos
Ficheiro de configuração zebra.conf do router zarolho:
!
! Zebra
configuration saved from vty
!
!
hostname
Router
password ******
enable
password ******
!
interface
rl0
ip address 192.168.1.125/24
ipv6 nd suppress-ra
!
interface
xl0
ip address 192.168.21.1/24
ipv6 nd suppress-ra
!
interface
lp0
ipv6 nd suppress-ra
!
interface
faith0
ipv6 nd suppress-ra
!
interface
lo0
!
interface
ppp0
ipv6 nd suppress-ra
!
interface
sl0
ipv6 nd suppress-ra
!
interface
gif0
ipv6 nd suppress-ra
!
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- enable password - indica a password necessária para a ceder ao modo privilegiado;
- ip address - indica o endereço IPv4 da interface;
- ipv6 nd suppress-ra - Indica que a interface não vai enviar router advertisements (IPv6).
Ficha de configuração ripd.conf do router zarolho:
!
! Zebra
configuration saved from vty
!
!
hostname
ripd
password ******
log stdout
!
interface
rl0
ip rip send version 1 2
ip rip receive version 1 2
!
interface
xl0
ip rip send version 1 2
ip rip receive version 1 2
!
interface
lp0
!
interface
faith0
!
interface
lo0
!
interface
ppp0
!
interface
sl0
!
router rip
network (192.168.1.0)
network (192.168.21.0)
network rl0
network xl0
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- ip rip send version - indica qual a versão do protocolo RIP que a interface irá enviar anúncios;
- ip rip receive version - indica qual a versão do protocolo RIP que a interface irá receber anúncios;
- network - existem dois tipos: network} <prefixos ip> e network <interface>. Indica quais as redes que se deve anunciar (prefixos ip) e por qual interface se vai enviar os anúncios.
Ficheiro de configuração zebra.conf do router zarolho:
!
! Zebra
configuration saved from vty
!
!
hostname
Router
password ********
!
interface
rl0
ipv6 address 3ffe:3102:fff6:1::2/64
no ipv6 nd suppress-ra
ipv6 nd prefix-advertisement
3ffe:3102:fff6:1::/64 2592000 604800 onlink
autoconfig
!
interface
xl0
ipv6 address 3ffe:3102:fff6:2::2/64
ipv6 nd suppress-ra
!
interface
lp0
ipv6 nd suppress-ra
!
interface
faith0
ipv6 nd suppress-ra
!
interface
lo0
!
interface
ppp0
ipv6 nd suppress-ra
!
interface
sl0
ipv6 nd suppress-ra
!
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- ipv6 address - indica o endereço IPv6 da interface;
- ipv6 nd suppress-ra - Indica que a interface não vai enviar router advertisements (IPv6) pela interface;
- no ipv6 nd suppress-ra - Indica que a interface vai enviar router advertisements (IPv6) pela interface;
- ipv6 nd prefix-advertisement - indica o prefixo de rede a anunciar no advertisement;
Ficheiro de configuração ripng.conf do router zarolho:
!
! Zebra
configuration saved from vty
!
!
hostname
ripngd
password *****
log stdout
!
interface
rl0
!
interface
xl0
!
interface
lp0
!
interface
faith0
!
interface
lo0
!
interface
ppp0
!
interface
sl0
!
!
router
ripng
network 3ffe:3102:fff6:2::2/64
network xl0
route 3ffe:3102:fff6:1::/64
route 3ffe:3102:fff6:2::/64
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- network - existem dois tipos: network <prefixos ip> e network <interface>. Indica quais as redes em que se vai anunciar (prefixos ip) e por qual interface se vai enviar os anúncios;
- route - quais os prefixos a anunciar.
Ficheiro de configuração /etc/rc.conf do \emph{router zarolho} (só o que foi acrescentado ao ficheiro):
#IPV6 config
ipv6_ifconfig_rl0="3ffe:3102:fff6:1::2 prefixlen 64"
ipv6_ifconfig_xl0="3ffe:3102:fff6:2::2
prefixlen 64"
Explicação das diversas linhas do ficheiro:
- ipv6\_ifconfig\_rl0 - atribui à
interface rl0 um endereço IPv6.
Ficheiro de configuração zebra.conf do router zeus:
!
! Zebra
configuration saved from vty
!
!
hostname
Router
password ******
!
interface
rl0
ipv6 address 3ffe:3102:fff6:2::1/64
ipv6 nd suppress-ra
!
interface rl1
ipv6 address 3ffe:3102:fff6:3::1/64
no ipv6 nd suppress-ra
ipv6 nd prefix-advertisement
3ffe:3102:fff6:3::/64 2592000 604800 onlink
autoconfig
!
interface
lp0
ipv6 nd suppress-ra
!
interface
faith0
ipv6 nd suppress-ra
!
interface
lo0
!
interface
ppp0
ipv6 nd suppress-ra
!
interface
sl0
ipv6 nd suppress-ra
!
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- ipv6 address - indica o endereço IPv6 da interface;
- ipv6 nd suppress-ra - Indica que a interface não vai enviar router advertisements (IPv6) pela interface;
- no ipv6 nd suppress-ra - Indica que a interface vai enviar router advertisements (IPv6) pela interface;
- ipv6 nd prefix-advertisement - indica o prefixo de rede a anunciar no advertisement;
Ficheiro de configuração ripng.conf do router zeus:
!
! Zebra
configuration saved from vty
!
!
hostname
ripngd
password *******
log stdout
!
interface
rl0
!
interface
rl1
!
interface
lp0
!
interface
faith0
!
interface
lo0
!
interface
ppp0
!
interface
sl0
!
!
router
ripng
network 3ffe:3102:fff6:2::1/64
network rl0
route 3ffe:3102:fff6:2::/64
route 3ffe:3102:fff6:3::/64
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- network - existem dois tipos: network <prefixos ip> e network <interface>. Indica quais as redes em que se vai anunciar (prefixos ip) e por qual interface se vai enviar os anúncios;
- route - quais os prefixos a anunciar.
Ligação à FCCN utilizando RIPng
Neste ambiente, os ficheiros de configuração são idênticos aos anteriores, somente difere no ripng.conf do router2 onde temos que enviar os anúncios para o túnel.
!
! Zebra
configuration saved from vty
!
!
hostname
ripngd
password ******
log stdout
!
interface
rl0
!
interface
xl0
!
interface
lp0
!
interface
faith0
!
interface
lo0
!
interface
ppp0
!
interface
sl0
!
interface
gif0
!
router
ripng
network 3ffe:3102:fff6:1::1/64
network 3ffe:31ff:0:ffff::41/64
network rl0
network gif0
route 3ffe:3102:fff6:1::/64
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- network - existem dois tipos: network <prefixos ip> e network <interface>. Indica quais as redes em que se vai anunciar (prefixos ip) e por qual interface se vai enviar os anúncios;
- route - quais os prefixos a anunciar.
Desta maneira os anúncios são enviados pelo túnel já referido para o \emph{router} da FCCN.
Ficheiro de configuração zebra.conf do zarolho:
!
! Zebra
configuration saved from vty
!
!
hostname
Router
password *****
enable
password *****
!
interface
rl0
ipv6 address 3ffe:3102:fff6:1::2/64
ipv6 nd suppress-ra
ipv6 nd prefix-advertisement
3ffe:3102:fff6:1::/64 2592000 604800 onlink
autoconfig
!
interface
xl0
ipv6 address 3ffe:3102:fff6:2::2/64
ipv6 nd suppress-ra
!
interface
lp0
ipv6 nd suppress-ra
!
interface
faith0
ipv6 nd suppress-ra
!
interface
lo0
!
interface
ppp0
ipv6 nd suppress-ra
!
interface
sl0
ipv6 nd suppress-ra
!
interface
gif0
ipv6 nd suppress-ra
!
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- ipv6 address - indica o endereço IPv6 da interface;
- ipv6 nd suppress-ra - Indica que a interface não vai enviar router advertisements (IPv6) pela interface;
- no ipv6 nd suppress-ra - Indica que a interface vai enviar router advertisements (IPv6) pela interface;
- ipv6 nd prefix-advertisement - indica o prefixo de rede a anunciar (advertisement) no interface;
Ficheiro de configuração isisd.conf do zarolho:
!
! Zebra
configuration saved from vty
!
!
hostname
isisd
password ******
log file
/tmp/isisd.log
!
interface
rl0
ipv6 router isis ipt
ipv6 address fe80::250:fcff:fe4a:9511/64
ipv6 address 3ffe:3102:fff6:1::2/64
isis circuit-type level-1
interface
rl1
ipv6 router isis ipt
ipv6 address fe80::2e0:4cff:fe77:eef/64
ipv6 address 3ffe:3102:fff6:2::2/64
isis circuit-type level-1
interface
lp0
interface
faith0
interface
lo0
interface
ppp0
interface
sl0
interface
rlo
!
router isis
ipt
net 49.0001.0001.0002.0023.00
is-type level-1
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- ipv6 router isis - indica qual a área a que a interface pertence, e a configuração da área;
- ipv6 address - indica o endereço IPv6 da interface;
- isis circuit-type - indica o nível em que a interface está inserida (ver: 2.3)
- net - indica o id do router e da área (49.0001 - área, 0001.0002.00023 - router id)
- is-type - indica em que nível está a área.
Ficheiro de configuração zebra.conf do zeus:
!
! Zebra
configuration saved from vty
!
!
hostname
Router
password *****
enable
password ******
!
interface
rl0
ipv6 address 3ffe:3102:fff6:2::1/64
ipv6 nd suppress-ra
!
interface
rl1
ipv6 address 3ffe:3102:fff6:3::1/64
no ipv6 nd suppress-ra
ipv6 nd prefix-advertisement 3ffe:3102:fff6:3::/64
2592000 604800 onlink
autoconfig
!
interface
lp0
ipv6 nd suppress-ra
!
interface
faith0
ipv6 nd suppress-ra
!
interface
lo0
!
interface
ppp0
ipv6 nd suppress-ra
!
interface
sl0
ipv6 nd suppress-ra
!
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- ipv6 address - indica o endereço IPv6 da interface;
- ipv6 nd suppress-ra - Indica que a interface não vai enviar router advertisements (IPv6) pela interface;
- no ipv6 nd suppress-ra - Indica que a interface vai enviar router advertisements (IPv6) pela interface;
- ipv6 nd prefix-advertisement - indica o prefixo de rede a anunciar (advertisement) no interface;
Ficheiro de configuração isisd.conf do zeus:
!
! Zebra
configuration saved from vty
!
!
hostname
isisd
password
proj#dei03
enable
password proj#dei03
log file
/tmp/isisd.log
!
interface
ed0
ipv6 router isis ipt
ipv6 address fe80::260:67ff:fe3d:51df/64
ipv6 address 3ffe:3102:fff6:3::1/64
isis circuit-type level-1
interface
rl0
ipv6 router isis ipt
ipv6 address fe80::24f:4eff:fe16:92ff/64
ipv6 address 3ffe:3102:fff6:2::1/64
isis circuit-type level-1
interface
lp0
interface
faith0
interface
lo0
interface
ppp0
interface
sl0
!
router isis
ipt
net 49.0001.0001.0002.0004.00
is-type level-1
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- ipv6 router isis - indica qual a área a que a interface pertence, e a configuração da área;
- ipv6 address - indica o endereço IPv6 da interface;
- isis circuit-type - indica o nível em que a interface está inserida (ver: 2.3)
- net - indica o id do router e da área (49.0001 - área, 0001.0002.00023 - router id)
- is-type - indica em que nível está a área.
Ligação à FCCN utilizando OSPFv3
Ficheiro de configuração zebra.conf do router2:
!
! Zebra
configuration saved from vty
!
!
hostname
Zebra
password
*******
!
interface
rl0
ipv6 nd suppress-ra
!
interface
rl1
ipv6 address 3ffe:3102:fff6:1::1/64
ipv6 nd suppress-ra
!
interface
lp0
ipv6 nd suppress-ra
!
interface
faith0
ipv6 nd suppress-ra
!
interface
lo0
!
interface
ppp0
ipv6 nd suppress-ra
!
interface
sl0
ipv6 nd suppress-ra
!
!
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- ipv6 address - indica o endereço IPv6 da interface;
- ipv6 nd suppress-ra - Indica que a interface não vai enviar router advertisements (IPv6) pela interface;
Ficheiro de configuração ospf6d.conf do router2:
!
! Zebra
configuration saved from vty
!
!
hostname
ospf6d
password
******
log file
/var/log/zebra-ospf6d.log
log stdout
!
debug ospf6
message dbdesc
debug ospf6
message lsreq
debug ospf6
message lsupdate
debug ospf6
message lsack
debug ospf6
neighbor
debug ospf6
interface
debug ospf6 lsa
debug ospf6 zebra
debug ospf6
config
debug ospf6
dbex
debug ospf6
spf
debug ospf6
route
debug ospf6
area
!
interface
rl1
ipv6 ospf6 cost 1
ipv6 ospf6 hello-interval 20
ipv6 ospf6 dead-interval 80
ipv6 ospf6 retransmit-interval 5
ipv6 ospf6 priority 1
ipv6 ospf6 transmit-delay 1
ipv6 ospf6 instance-id 0
!
interface
gif0
ipv6 ospf6 cost 1
ipv6 ospf6 hello-interval 20
ipv6 ospf6 dead-interval 80
ipv6 ospf6 retransmit-interval 5
ipv6 ospf6 priority 1
ipv6 ospf6 transmit-delay 1
ipv6 ospf6 instance-id 0
!
!
router
ospf6
router-id 193.139.65.223
redistribute connected
redistribute static
interface rl1 area 0.0.0.1
interface gif0 area 0.0.0.0
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- ipv6 ospf6 cost - indica o custo da interface;
- ipv6 ospf6 hello-interval - indica o intervalo de tempo de envio dos pacote hello;
- ipv6 ospf6 dead-interval - indica o tempo de vida dos registos nas tabelas;
- ipv6 ospf6 retransmit-interval - indica o tempo em que vai voltar a transmitir;
- ipv6 ospf6 priority - indica a prioridade do router, para a eleição de designated router;
- ipv6 ospf6 transmit-delay - indica o delay de transmissão;
- ipv6 ospf6 instance-id - indica o id da instância;
- router-id - indica o id do router;
- redistribute connected - redistribui as rotas que estão conectadas;
- redistribute static - redistribui as rotas estáticas;
- interface gif0 area 0.0.0.0 - indica que a interface gif0 pertence à área 0.0.0.0 (backbone).
Todos os restantes campos neste ficheiro de configuração (ipv6 ospf6 hello-interval, etc.) foram referidos anteriormente.
Ficheiro de configuração /etc/rc.conf do router2 (só o que foi acrescentado ao ficheiro):
#Routing IPv6 configuration
defaultrouter="134.136.25.257"
ipv6_ifconfig_rl1="3ffe:3102:fff6:1::1 prefixlen 64"
ifconfig_rl0="inet 193.139.65.223 netmask 255.255.255.0"
Explicação das diversas linhas do ficheiro:
- ipv6\_ifconfig\_rl1 - atribui à interface rl1 um endereço IPv6;
- ifconfig\_rl0 - atribui um endereço IPv4 à interface rl0;
- defaultrouter - atribui um gateway IPv4 à máquina.
Ficheiro de configuração zebra.conf
do router zarolho:
!
! Zebra
configuration saved from vty
!
!
hostname Router
password *******
!
interface
rl0
ipv6 address 3ffe:3102:fff6:1::2/64
no ipv6 nd suppress-ra
ipv6 nd prefix-advertisement
3ffe:3102:fff6:1::/64 2592000 604800 onlink
autoconfig
!
interface
xl0
ipv6 address 3ffe:3102:fff6:2::2/64
ipv6 nd suppress-ra
!
interface
lp0
ipv6 nd suppress-ra
!
interface
faith0
ipv6 nd suppress-ra
!
interface
lo0
!
interface
ppp0
ipv6 nd suppress-ra
!
interface
sl0
ipv6 nd suppress-ra
!
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- ipv6 address - indica o endereço IPv6 da interface;
- ipv6 nd suppress-ra - Indica que a interface não vai enviar router advertisements (IPv6) pela interface;
- no ipv6 nd suppress-ra - Indica que a interface vai enviar router advertisements (IPv6) pela interface;
- ipv6 nd prefix-advertisement - indica o prefixo de rede a anunciar (advertisement) no interface;
Ficheiro de configuração ospf6d.conf do router zarolho:
!
! Zebra configuration saved from vty
!
!
hostname ospf6d
password proj#dei03
log file /var/log/zebra-ospf6d.log
log stdout
!
debug ospf6 message dbdesc
debug ospf6 message lsreq
debug ospf6 message lsupdate
debug ospf6 message lsack
debug ospf6 neighbor
debug ospf6 interface
debug ospf6 lsa
debug ospf6 zebra
debug ospf6 config
debug ospf6 dbex
debug ospf6 spf
debug ospf6 route
debug ospf6 area
!
interface rl0
ipv6
ospf6 cost 1
ipv6
ospf6 hello-interval 20
ipv6
ospf6 dead-interval 80
ipv6
ospf6 retransmit-interval 5
ipv6
ospf6 priority 90
ipv6
ospf6 transmit-delay 1
ipv6
ospf6 instance-id 0
!
!
router ospf6
router-id 192.168.1.125
redistribute connected
redistribute static
redistribute ripng
interface rl0 area 0.0.0.1
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para entrar no ambiente zebra;
- ipv6 ospf6 cost - indica o custo da interface;
- ipv6 ospf6 hello-interval - indica o intervalo de tempo de envio dos pacote hello;
- ipv6 ospf6 dead-interval - indica o tempo de vida dos registos nas tabelas;
- ipv6 ospf6 retransmit-interval - indica o tempo em que vai voltar a transmitir;
- ipv6 ospf6 priority - indica a prioridade do router, para a eleição de designated router;
- ipv6 ospf6 transmit-delay - indica o delay de transmissão;
- ipv6 ospf6 instance-id - indica o id da instância;
- router-id - indica o id do router;
- redistribute connected - redistribui as rotas que estão conectadas;
- redistribute static - redistribui as rotas estáticas;
- redistribute ripng - redistribui as rotas de ripng;
- interface rl0 area 0.0.0.1 - indica que a interface rl0 pertence à área 0.0.0.1 (backbone).
Ficheiro de configuração ripng.conf do router zarolho:
!
! Zebra
configuration saved from vty
!
!
hostname
ripngd
password
proj#dei03
log stdout
!
interface
rl0
!
interface
xl0
!
interface
lp0
!
interface
faith0
!
interface
lo0
!
interface
ppp0
!
interface
sl0
!
!
router
ripng
network 3ffe:3102:fff6:2::2/64
network xl0
redistribute kernel
redistribute connected
redistribute static
redistribute ospf6
route 3ffe:3102:fff6:1::/64
route 3ffe:3102:fff6:2::/64
!
line vty
!
Explicação das diversas linhas do ficheiro:
- hostname - indica o nome da prompt no ambiente zebra (telnet);
- password - indica a password que é necessária para
entrar no ambiente zebra;
- network - existem dois tipos: network <prefixos ip> e network <interface>. Indica quais as redes em que se vai anunciar (prefixos ip) e por qual interface se vai enviar os anúncios;
- redistribute kernel - redistribui as rotas de kernel;
- redistribute connected - redistribui as rotas que estão conectadas;
- redistribute static - redistribui as rotas estáticas;
- redistribute ripng - redistribui as rotas de ripng;
- route - quais os prefixos a anunciar.
Ficheiro de configuração /etc/rc.conf do zarolho (só o que foi acrescentado ao ficheiro):
#IPV6 config
ipv6_defaultrouter="3ffe:3102:fff6:1::1"
ipv6_ifconfig_rl0="3ffe:3102:fff6:1::2
prefixlen 64"
ipv6_ifconfig_xl0="3ffe:3102:fff6:2::2
prefixlen 64"
Explicação das diversas linhas do ficheiro:
- ipv6\_ifconfig\_rl0 - atribui à interface rl0 um endereço IPv6;
- ipv6\_defaultrouter} - atribui um gateway IPv6 à máquina.
O zeus mantém a mesma configuração do anexo 2.